

你搭了Prometheus和Grafana,仪表盘很漂亮,CPU、内存、磁盘曲线一目了然。然后你把它关掉,再也没看过。
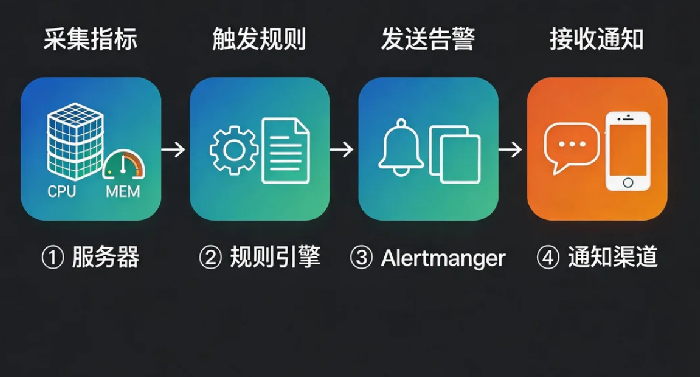
监控不是用来“看”的,是用来“触发行动”的。你不可能24小时盯着仪表盘。你需要的是——出问题了,它主动找你。
今天把Prometheus的告警组件Alertmanager配起来。CPU超了,给你发钉钉。磁盘满了,给你发企业微信。网站挂了,给你发邮件。你不需要盯着屏幕,问题会自己来找你。
先看一个数据
某运维团队,在用Prometheus之前,平均故障发现时间约15分钟(用户投诉才知道)。接入告警后,缩短到1分钟以内。不是他们变强了,是他们从“被动等投诉”变成了“主动等告警”。15分钟 vs 1分钟,差别是1500个用户的糟糕体验。
Alertmanager是什么?
Prometheus负责采集指标、存储数据、执行告警规则。当规则触发时,Prometheus把告警发给Alertmanager。Alertmanager负责:去重(同一类告警5分钟内只发一次)、分组(把同一台服务器的多个告警合并成一条)、路由(CPU告警发运维群,磁盘告警发存储群)、抑制(服务器挂了,就不再发该服务器上的其他告警)。
它不负责判断要不要告警,只负责决定怎么通知你。
第一步:安装Alertmanager
bash
# 下载 wget https://github.com/prometheus/alertmanager/releases/download/v0.27.0/alertmanager-0.27.0.linux-amd64.tar.gz tar -xzf alertmanager-0.27.0.linux-amd64.tar.gz cd alertmanager-0.27.0.linux-amd64 # 移到系统目录 sudo mv alertmanager /usr/local/bin/ sudo mkdir -p /etc/alertmanager sudo mv alertmanager.yml /etc/alertmanager/
创建systemd服务/etc/systemd/system/alertmanager.service:
ini
[Unit] Description=Alertmanager After=network.target [Service] ExecStart=/usr/local/bin/alertmanager --config.file=/etc/alertmanager/alertmanager.yml Restart=always [Install] WantedBy=multi-user.target
启动并设置开机自启:
bash
sudo systemctl daemon-reload sudo systemctl start alertmanager sudo systemctl enable alertmanager
访问http://你的IP:9093,看到Alertmanager界面,说明部署成功。
第二步:配置告警规则(Prometheus端)
创建告警规则文件/etc/prometheus/alerts.yml:
yaml
groups:
- name: instance-alerts
interval: 30s
rules:
# CPU使用率 > 80%
- alert: HighCPUUsage
expr: (100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "CPU使用率过高"
description: "实例 {{ $labels.instance }} CPU使用率已超过80%,当前值 {{ $value }}%"
# 内存使用率 > 90%
- alert: HighMemoryUsage
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 90
for: 5m
labels:
severity: warning
annotations:
summary: "内存使用率过高"
description: "实例 {{ $labels.instance }} 内存使用率已超过90%,当前值 {{ $value }}%"
# 磁盘使用率 > 85%
- alert: HighDiskUsage
expr: (node_filesystem_size_bytes{fstype=~"ext4|xfs"} - node_filesystem_free_bytes{fstype=~"ext4|xfs"}) / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100 > 85
for: 5m
labels:
severity: warning
annotations:
summary: "磁盘使用率过高"
description: "实例 {{ $labels.instance }} 挂载点 {{ $labels.mount }} 磁盘使用率超过85%,当前值 {{ $value }}%"
# 实例下线(up=0)
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "实例下线"
description: "实例 {{ $labels.instance }} 已下线超过1分钟"
在Prometheus配置文件/etc/prometheus/prometheus.yml中加载这个规则文件:
yaml
rule_files: - "alerts.yml"
并配置Alertmanager地址:
yaml
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
重启Prometheus:
bash
sudo systemctl restart prometheus
访问Prometheus的Alerts页面(http://你的IP:9090/alerts),能看到刚才定义的规则。
第三步:配置通知渠道(Alertmanager端)
编辑/etc/alertmanager/alertmanager.yml:
yaml
global:
smtp_smarthost: 'smtp.example.com:587'
smtp_from: 'alertmanager@example.com'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 12h
receiver: 'webhook'
receivers:
- name: 'webhook'
webhook_configs:
- url: 'https://your-webhook-url'
send_resolved: true
配置钉钉/企业微信机器人时,Alertmanager本身不直接对接,需要一个中间转换服务(如prometheus-webhook-dingtalk)。简化版做法:用webhook接收告警,再转发给钉钉。
对接钉钉(详细步骤)
1. 在钉钉群里添加机器人:群设置 → 智能群助手 → 添加机器人 → 自定义 → 设置关键词“告警”,复制webhook URL。
2. 下载prometheus-webhook-dingtalk:
bash
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.1.0/prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz tar -xzf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz cd prometheus-webhook-dingtalk-2.1.0.linux-amd64 sudo mv prometheus-webhook-dingtalk /usr/local/bin/
3. 创建配置目录和目标地址(示例中通过参数直接指定):
bash
/usr/local/bin/prometheus-webhook-dingtalk --ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=你的token"
4. 创建systemd服务启动转换器,然后在Alertmanager的receiver里把webhook地址指向http://localhost:8060/dingtalk/webhook1/send。
5. 重启Alertmanager。
现在,当告警触发时,你会在钉钉群里收到消息。
配置企业微信
企业微信机器人配置类似。webhook URL格式:
text
https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=你的key
用prometheus-webhook-dingtalk同样可以转发。或直接用curl脚本。
告警规则编写技巧
持续多久再告警:for: 5m,CPU超过80%持续5分钟才发告警,避免瞬时波动打扰你。
重要程度分级:severity: critical(严重)和warning(警告),不同级别发不同群。
抑制规则:服务器挂了就别再发CPU告警了。在Alertmanager里配置inhibit_rules。
不在半夜打扰:在路由里配置time_range,比如晚上12点到早上8点,把warning级别告警静音。
真实案例
一家电商公司,用Prometheus+Alertmanager监控了50台服务器。有一天凌晨3点,某个数据库服务器的磁盘使用率超过了85%,告警发到钉钉群。运维被手机震醒,登录上去一看,日志文件忘了轮转。清理后,磁盘恢复。
如果没有告警,磁盘会继续涨到100%,数据库在早上高峰期因无法写入而挂掉。
负责人说:“凌晨3点被吵醒很难受,但比早上8点被用户骂醒好受。”
最后一句
Prometheus的价值不只是仪表盘。仪表盘是给你看的,告警是替你看的。配置好告警,你不需要主动去发现问题,问题会自动来找你。
把Alertmanager搭起来,把钉钉/企业微信/邮箱配好,把常用的CPU、内存、磁盘、实例存活告警加上。从此告别半夜被用户叫醒。
你的服务器会替你发消息。你的手机只需要接收。