

你看监控:CPU从10%突然跳到90%,又落回20%。过几分钟又来一次。网站时快时慢,用户投诉,你却找不到规律。
CPU不是持续高,而是周期性波动。这种情况比持续100%更难排查。
今天把常见原因和排查思路整理出来。
先看一个数据
周期性CPU峰值往往由计划任务触发。定时任务、备份脚本、日志轮转、索引重建,这些操作集中在特定时间点执行,让CPU呈现有规律的高负载。另一类波动没有固定规律,可能来自突发流量、应用行为或系统内部事件。
通过查看/var/log/syslog中的CRON记录,你可以确认定时任务是否与高峰时间吻合。
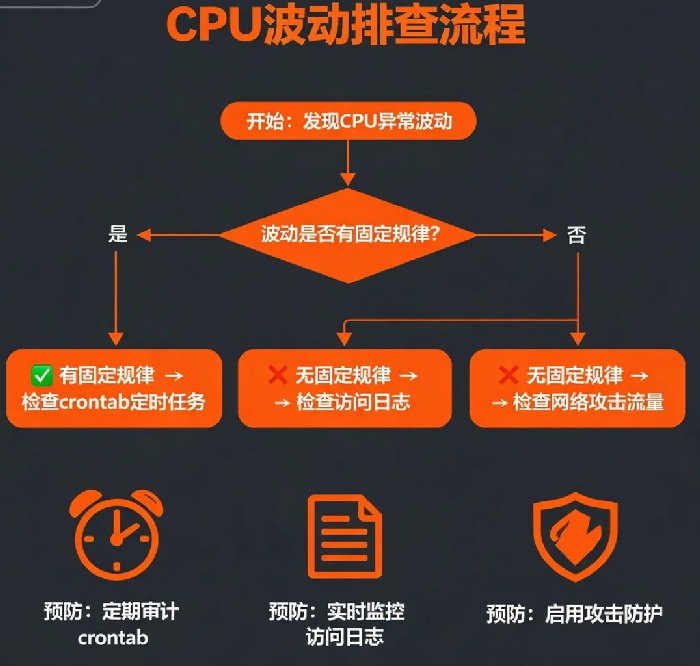
排查一:先确认规律
观察CPU波动的模式,判断是有规律还是无规律。
用监控看趋势:
- 每天固定时间点飙升 → 定时任务
- 随机无规律飙升 → 流量波动或异常进程
- 缓慢爬升后下降 → 内存泄漏或资源累积
用top实时观察,或者用htop查看更直观的CPU历史。如果波动时间固定,先查crontab。
排查二:检查定时任务
定时任务是周期性CPU飙升的常见原因。
bash
crontab -l cat /etc/crontab ls -la /etc/cron.d/ ls -la /etc/cron.hourly/ ls -la /etc/cron.daily/ ls -la /etc/cron.weekly/
常见定时任务引发的CPU峰值:
- 备份脚本:凌晨2点执行数据库备份(CPU+磁盘I/O)
- 日志轮转:logrotate压缩旧日志(CPU)
- 更新任务:
apt update或yum check-update - 索引重建:搜索服务定期重建索引
- 清理脚本:定时清理临时文件
检查这些任务是否与CPU飙升时间吻合。如果某个任务造成明显负载,考虑调整执行时间或优化脚本。
排查三:检查应用层面的周期任务
应用内部也可能有定时操作:
Java应用:
- Full GC(垃圾回收)会暂停应用并消耗CPU
- 用
jstat -gcutil PID查看GC频率和耗时
PHP应用:
- 计划任务(如WordPress的wp-cron)
- 队列处理(如Laravel的queue:work)
数据库:
- 慢查询可能在特定时间执行
- 统计信息更新、索引重建
排查四:检查是否有外部攻击
不是所有波动都是业务导致的。
被扫描:攻击者在特定时间段发起扫描,CPU瞬时升高。
被CC攻击:大量请求集中在短时间内,CPU飙升。
bash
# 查看当时的访问日志 grep "2026-07-02:14" /var/log/nginx/access.log | wc -l # 对比正常时段的请求量
如果访问量突然翻了几倍甚至几十倍,检查日志中的IP是否集中,确认是否为恶意请求。
排查五:检查系统级别的事件
某些系统事件也会消耗CPU:
内存回收:内存不足时,kswapd0进程回收内存,消耗CPU。
bash
vmstat 1 # 观察si/so列,如果持续>0,说明内存不足
文件系统缓存回收:脏页回写(flush进程)可能造成CPU峰值。
真实案例
一台服务器CPU每2小时出现一次30秒的峰值。监控确认时间固定,检查/etc/cron.d/发现一个脚本每2小时执行一次,脚本内容是对一个100万行的数据库表执行REINDEX。将该任务调整到凌晨执行后,白天CPU波动消失。
预防措施
- 错开定时任务:不要让所有定时任务集中在同一时间
- 监控告警:设置CPU波动的告警阈值
- 任务调度优化:将重任务分散到不同时间段执行
- 限流措施:对API和关键接口做限流
- 定时任务规范:用日志记录任务执行时间,便于事后追踪
最后一句
CPU忽高忽低通常有迹可循。先确定是否有固定规律,有规律查定时任务,无规律查访问日志和进程。top和crontab是你最常用的工具。
周期性波动大多是定时任务造成的。如果排除了定时任务还找不到原因,看访问日志和系统日志。波动不是无缘无故的——它一定有来源,只是你还没找到。