

打开上月云账单时,你是不是也经常感到一种无力感?
屏幕上罗列着上百项服务,从“亚太-香港 区域-标准存储-存储容量”到“欧盟-法兰克福 2 vCPU 4 GiB 计算实例”,密密麻麻的数字和术语交织成一张天书。大多数团队的反应是直接翻到最后一页,看着那个触目惊心的总金额,然后召开紧急会议,下达一个模糊的指令:“下个月,我们必须降低成本!”
结果呢?大家开始漫无目的地关闭实例、清理存储,像在黑暗中挥舞拳头,不知道目标在哪。一个月后,某些费用确实下降了,但总有其他费用神秘地上升,总成本依然坚挺。
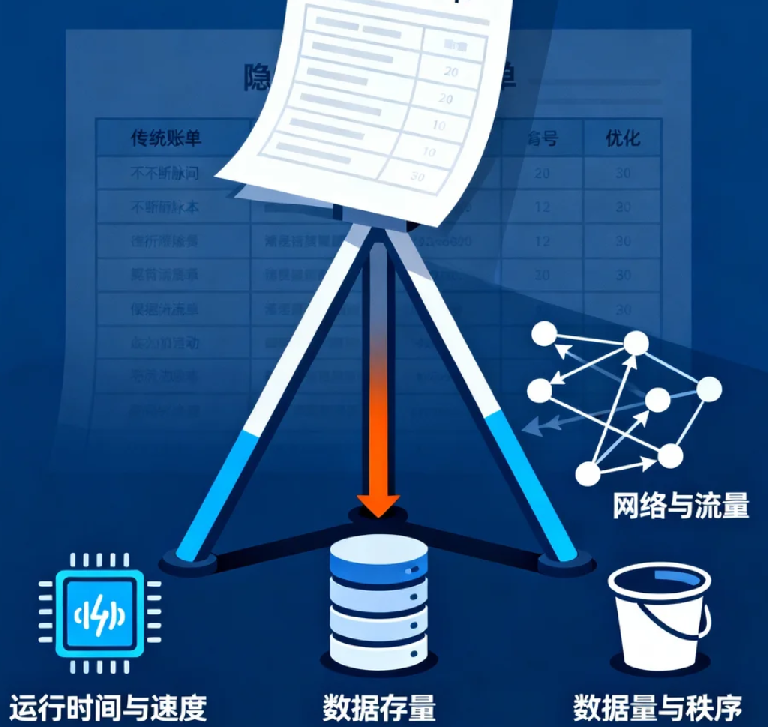
是时候换一种思维方式了。今天,让我们回归第一性原理,像拆解一个复杂的工程问题一样,拆解你的云账单。忘掉那几十个令人困惑的服务名称,所有云成本,归根结底都由三个,且仅由三个核心因子驱动:
- 计算容量:你的代码运行了多久,多快。
- 数据存量:你的数据存储了什么,存储了多少。
- 数据流动:你的数据在哪里移动,移动了多少。
理解并掌控这三者,你就能从云成本的被动承受者,转变为主动的设计师。
第一驱动因子:计算容量——为“时间”与“空间”付费
核心本质: 你租用的是“CPU周期”和“内存字节”在特定时间内的使用权。
这就像租房,你不仅为空间(户型大小)付费,也为时间(租期)付费。云上的计算服务,无论包装成EC2、Lambda还是容器,都逃不开这个基础模型。
反常规视角1:你支付的“闲置资源”,是云上最昂贵的奢侈品。
一个持续运行但平均CPU利用率只有5%的虚拟机,其浪费程度堪比在北京国贸租下一整层办公楼,却只放了一张办公桌。根据业界基准,大多数生产虚拟机的平均CPU利用率徘徊在5%-15%之间。这意味着,你支付的超过80%的计算资源,都在默默地“陪跑”,没有产生任何价值。
如何驯服“计算”这头巨兽?
- 从“静态占有”到“动态匹配”:放弃那种“买定离手”的虚拟机采购思维。利用弹性伸缩组、Kubernetes HPA等工具,让你的计算资源池像呼吸一样,随着业务流量自然地扩张与收缩。
- 拥抱“任务粒度”:对于那些不需要持续运行的后台任务、数据处理job,坚决使用Serverless函数(如AWS Lambda)。你将为每次执行的毫秒级时长付费,而不是为“它可能被用到”的24/7/365付费。这能将特定工作负载的成本降低1-2个数量级。
第二驱动因子:数据存量——为“熵减”付费
核心本质: 你支付的不是存储数据本身,而是为对抗“数据无序化”(熵增)所付出的能量和秩序。
云存储服务,本质上是一个高度有序、安全、可用的“数据保险库”。维持这个秩序,需要成本。
反常规视角2:最贵的存储,是“你不知道有什么用,但又不敢删”的存储。
我们习惯于将数据存储成本视为廉价的、一次性的。但真正的成本是复合的。它不仅是每GB/月的费用,还包括:
- 备份与快照成本:你的主存储数据,会像细胞分裂一样,衍生出大量的备份和快照。这些副本的成本常常与主数据相当,甚至更高,且极易被遗忘。
- 检索成本:尤其是在归档存储中,将数据“唤醒”的成本可能远超你的存储支出。
- 安全与合规成本:为敏感数据加密、审计、访问控制所付出的管理开销,是另一笔无形的税。
如何为“数据存量”瘦身?
- 实施数据生命周期法:像管理库存一样管理你的数据。定义清晰的策略:热数据存多久后转为温数据?温数据存多久后转入冷归档?一年都没被访问过的数据,是否应该被自动清理?一个自动化的生命周期策略,通常能削减30%-50%的整体存储支出。
- 定期进行“数据考古”:每季度,让技术负责人与业务负责人一起,审查最大的那些存储桶。逐一确认:“这些数据现在谁在用?用来做什么?如果删除,会对业务产生什么影响?”你会惊讶地发现,大量“僵尸数据”就此现形。
第三驱动因子:数据流动——为“位移”付费
核心本质: 数据在不同“位置”之间移动所产生的网络流量费。
这是最隐蔽、最反直觉,也最容易被忽视的驱动因子。在云的世界里,距离是有价的。
反常规视角3:你的微服务架构,可能正在无声地燃烧预算。
一个经典的误区是只关注“公网出网流量”这笔“明账”。而真正的网络成本黑洞,往往藏在“内账”里:
- 可用区(AZ)间流量:当你为了高可用,将服务部署在同一个区域的不同可用区时,它们之间的每一次数据交互(例如,应用服务器调用另一个可用区的数据库),都会产生昂贵的跨可用区流量费。这笔费用通常是公网入网流量的10倍以上。
- 区域间流量:在不同的地理区域(如从美东到美西)之间同步或迁移数据,成本更高。
- 服务间流量:使用云厂商的消息队列、数据湖分析等服务时,其内部的数据移动同样会计费。
一个设计不佳的微服务架构,其中频繁、细粒度的服务调用穿梭于不同可用区之间,其产生的网络成本可能轻松超过计算和存储成本的总和。
如何规划“数据流动”的路径?
- 架构设计遵循“数据就近”原则:确保紧密通信的服务和数据库部署在同一个可用区内。将数据的处理(计算)尽可能地移动到数据所在的地方,而不是反过来移动数据。
- 可视化你的数据流:使用云厂商的网络流量监控工具,绘制出一张“成本热力图”。一眼就能看出哪些可用区之间、哪些服务之间的数据流动最为昂贵,从而找到优化的突破口。
结语:从会计到架构师
现在,请你再次打开那份令人头痛的云账单。忘掉那些复杂的服务名称,试着用红、黄、蓝三支笔,将每一项费用归类到这三个核心驱动因子中。
你会发现,混沌立刻变得清晰。那个巨额数字,不再是无法理解的黑盒,而是由“计算”、“存储”、“网络”这三个清晰杠杆共同作用的结果。
那位曾经无助的CTO,在应用这个方法后告诉我:“我们不再说‘要降低云成本’这种空话了。现在我们开会,讨论的是‘如何优化这三个季度的数据跨区传输’、‘如何将这批计算任务从持续运行改为事件触发’。我们的优化,终于有了清晰的靶心。”
这就是第一性原理的力量。它让你穿透现象的迷雾,直击问题的本质。
你不是云资源的被动消费者。通过设计你的计算模式、管理你的数据生命周期、规划你的数据流动路径,你完全有能力亲手设计你的云成本结构。