

凌晨三点,监控大屏上所有核心指标一片绿色,CPU使用率45%,内存占用率62%,网络I/O平稳。然而,你的手机却被业务部门打爆——用户投诉支付订单全部失败,而你的仪表盘对此一无所知。
这个令人沮丧的场景暴露了现代可观测性建设的普遍困境:我们收集了海量指标、日志和追踪数据,却依然在关键时刻对系统的真实健康状况视而不见。
根据权威报告,尽管可观测性工具投入持续增长,但仍有超过 65% 的企业无法在系统异常影响用户前一小时内发出有效告警。更令人警醒的是,平均每次严重故障的诊断时间中,超过 70% 被浪费在筛选无关数据和验证错误假设上。
问题不在于数据太少,而在于我们问错了问题。我们痴迷于监控“系统是否在运行”,却忽略了回答“业务是否在健康地工作”。
01 黄金信号的诞生:从“系统体征”到“业务脉搏”
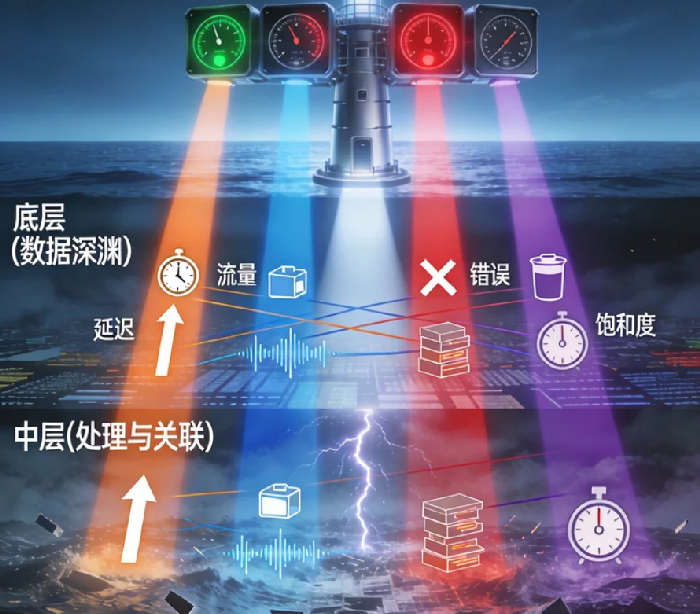
2003年,Google的SRE团队面临着一个根本性挑战:如何用最少但最关键的指标,判断一个复杂分布式系统的真实健康状况?他们的答案是四大黄金信号:延迟、流量、错误和饱和度。
这四项指标的精妙之处在于,它们共同构成了一个完整的稳定性感知框架:
- 延迟:系统响应请求所需时间,直接决定用户体验
- 流量:系统正在处理的请求量,反映负载压力
- 错误:请求处理失败的比例,衡量服务可靠性
- 饱和度:系统资源“吃饱”的程度,预示未来风险
这四大信号之间存在着精密的动态关系。研究表明,在微服务架构中,当延迟增加1%,往往会导致下游服务的错误率同步上升约0.5%-2%,这种链式反应在复杂依赖关系中会被放大。这意味着你观察任何一个信号时,必须同时考虑其他三个信号的关联变化。
反常规的视角是:在四大黄金信号中,流量可能是唯一纯粹的“好”信号。更多的流量通常意味着健康的业务增长,而延迟、错误和饱和度的任何异常变动,几乎总是坏事。
02 延迟:被平均值欺骗的“长尾杀手”
延迟是最直观的用户体验指标,但传统的平均延迟统计是一个危险的谎言。想象一下:99个请求在100毫秒内完成,1个请求需要10秒——平均延迟仅为199毫秒,看起来“良好”,但那个等了10秒的用户可能永远不会再回来。
在分布式系统中,延迟分布遵循的是长尾分布,而非正态分布。这意味着极端高延迟的请求虽然数量少,但对用户体验的破坏却是灾难性的。根据行业数据,P99延迟(最慢的1%请求)通常是P50延迟(中位数)的3到10倍,在资源争用激烈时,这一差距可能扩大到百倍以上。
因此,真正的延迟监控必须关注百分位数,而非平均值。一个实用的策略是:
- P50延迟作为日常健康基准
- P95延迟作为性能退化预警线
- P99延迟作为必须立即干预的红色警报
更深入的洞察来自延迟分解。通过分布式追踪,你可以看到一个10秒的API响应时间中,8秒耗费在数据库查询,1.5秒耗费在第三方服务调用,只有0.5秒是你的业务逻辑处理时间。这种细粒度分析将模糊的“系统慢”转化为具体的“数据库索引缺失”或“第三方接口超时”。
03 流量:最被低估的稳定性先知
流量往往被视为简单的计数器,但其变化模式蕴含着丰富的稳定性信息。正常的业务流量会呈现规律的周期模式——日高峰、周低谷、季节性波动。任何偏离这一模式的异常,都可能是稳定性风险的早期征兆。
这里有一个反直觉的发现:流量下降可能是比流量激增更危险的信号。流量激增通常引起团队的高度关注和快速扩容,而流量无声下降可能意味着:
- 上游服务故障导致请求无法到达
- 用户体验恶化导致用户流失
- 竞争对手活动或市场变化
一个实用的流量分析方法是将当前流量与历史基线比较。不要使用固定阈值(如“QPS超过1000告警”),而应使用基于历史数据的动态范围。例如,工作日上午10点的正常流量范围可能是800-1200 QPS,而凌晨3点的范围是50-100 QPS。同一绝对数值在不同时间具有完全不同的意义。
更高级的流量分析涉及流量构成的变化。如果总流量稳定,但来自某个特定用户群或地区的流量比例发生突变,这可能预示着定向攻击、区域故障或产品改动带来的意外影响。
04 错误:从计数到根因的智能关联
错误率是系统健康的直接体温计,但简单的错误计数远远不够。核心挑战在于错误分类与优先级划分:一个偶尔的第三方服务超时,与一个持续的内部逻辑错误,对系统稳定性的威胁完全不同。
现代系统的错误模式呈现出复杂特征。研究发现,在微服务架构中,超过40% 的异常是由间接依赖引起的——你的服务运行正常,但它依赖的下游服务出了问题。这意味着错误分析必须跨越服务边界,建立完整的依赖图谱。
黄金信号之间的一个关键关联是:错误率对延迟变化极为敏感。实验数据显示,当服务延迟超过某个临界点(通常是P95延迟的2倍),错误率会呈指数级增长而非线性增长。这意味着控制延迟不仅是性能优化,更是错误预防。
一个实用的错误管理策略是建立错误预算概念。与其追求不切实际的“零错误”,不如为每个服务定义可接受的错误率上限(如0.1%),并将这一预算作为开发、测试和发布的约束条件。当错误预算即将耗尽时,自动触发“代码冻结”或“回滚预案”,将稳定性风险前置管理。
05 饱和度:资源耗尽前的最后警报
饱和度是最容易被误解的黄金信号。它不只是CPU使用率或内存占用率,而是系统距离性能极限还有多远的综合度量。
传统监控常犯的错误是关注资源使用率的绝对值,而忽略其趋势和预测。CPU使用率80%本身可能不是问题,但如果它在过去一小时内从30%线性增长到80%,那么极有可能在接下来几小时内达到100%并引发故障。
在云原生环境中,饱和度的衡量需要多层次视角:
- 基础设施层:CPU、内存、磁盘I/O、网络带宽
- 中间件层:数据库连接池、消息队列深度、缓存命中率
- 应用层:线程池使用率、请求队列长度、垃圾回收频率
一个被低估的饱和度指标是排队理论的应用。利特尔法则告诉我们:系统中的平均请求数 = 平均到达率 × 平均响应时间。当请求开始排队时,延迟会非线性增长,这一效应在饱和度超过70%时变得尤为明显。
06 实践框架:从信号收集到稳定性决策
建立有效的黄金信号监控不是安装一个仪表盘那么简单,而是一个完整的工程实践体系:
第一层:信号定义与采集
为每个服务明确定义四大黄金信号的业务含义和采集方式。例如,一个用户服务的“错误”可能包括:身份验证失败、余额不足、网络超时,但不应包括正常的“用户不存在”业务逻辑。
第二层:基线建立与异常检测
基于历史数据为每个信号建立动态基线,使用统计学方法(如3σ原则、移动平均)识别异常。避免固定阈值,采用自适应算法适应业务周期和增长趋势。
第三层:关联分析与根因定位
当任一信号异常时,自动关联分析其他三个信号和相关事件(如最近的部署、配置变更、依赖服务状态)。使用相关性分析和因果推断技术减少误报,加速问题定位。
第四层:决策支持与自动化响应
将黄金信号转化为具体的运维决策。例如:
- 当延迟P99增加且错误率上升时:自动实施限流或降级
- 当流量异常下降且饱和度降低时:触发服务健康检查
- 当错误预算消耗过快时:阻止高风险部署或触发自动回滚
一个成功的实践案例来自某大型电商平台。他们通过实施基于黄金信号的稳定性框架,将严重故障的平均检测时间从 47分钟缩短到 4分钟,平均恢复时间从 2.5小时减少到 18分钟。关键突破在于他们不仅监控信号,还建立了信号间的因果模型,使系统能够预测而不仅仅是反应。
当你的监控系统不再只是记录“发生了什么”,而是开始回答“为什么会发生”和“接下来会发生什么”时,你就真正掌握了可观测性的精髓。
四大黄金信号之所以“黄金”,不是因为它们提供了所有的答案,而是因为它们提出了最正确的问题。在数据洪流中,它们是指引你关注真正重要变化的导航星图。
最成熟的可观测性实践,不是用最炫酷的仪表盘展示最多的数据,而是用最简单清晰的信号,让团队对系统稳定性建立最准确的“体感”。 当每一个工程师都能像老中医一样,通过“望闻问切”四大黄金信号,就判断出系统的健康状况和病灶所在时,稳定性才真正从被动救火变成了主动养生。
从这个角度看,可观测性建设的终极目标,是让系统学会“表达”自己的不适,让团队学会“倾听”系统的诉求。而黄金信号,就是这种对话中最共通、最精确的语言。