

网站打不开了。或者很慢。或者时好时坏。
你第一反应是什么?重启。重启不行?重启第二次。
重启确实能解决一部分问题,但大部分问题会复发。因为你只治了症状,没找到病因。
真正的做法是系统性地排查。这套流程我用了十年,从个人博客到大型电商,从Linux到Windows,从单机到集群,一直管用。今天分享给你。
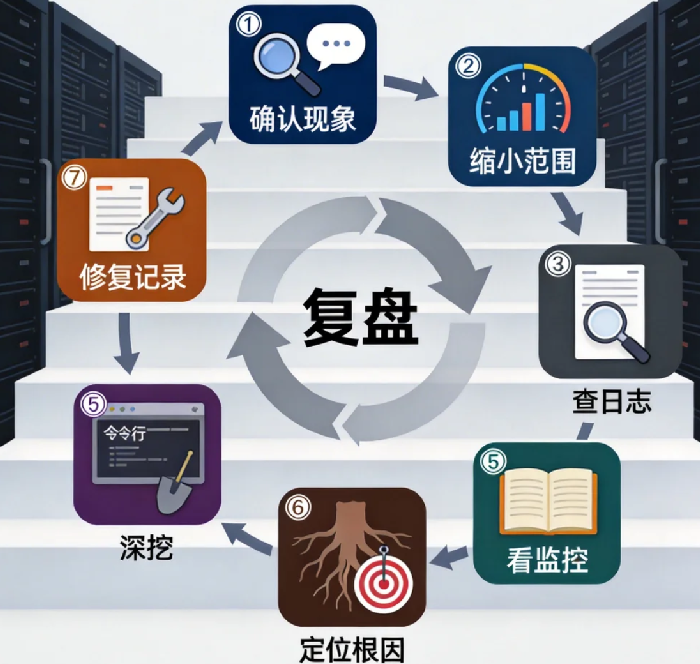
第一步:确认现象——别听用户说“网站打不开”
用户报故障的时候,通常只有一句话:“网站打不开了。”
这句话信息量几乎为零。你得把它拆开:
- 是所有用户都打不开,还是只有某个人?
- 是报错(502、500、404)还是慢?
- 什么时候开始的?最近改过什么?
有时候你会发现,用户说的“网站打不开”,其实是他的WiFi断了。
反常识点:我见过太多人冲进服务器折腾半天,最后发现是用户的本地DNS问题。所以第一步不是登服务器,是搞清楚到底发生了什么。
第二步:缩小范围——是服务器问题还是网络问题
登服务器之前,先在外面测一下:
- 你自己能不能打开?换手机网络再试一次(绕过本地网络)。
ping 你的域名,看IP对不对,通不通。telnet 你的域名 80或curl -I 你的域名,看能不能连上。
如果外面能打开,只有你自己打不开,那是你本地的问题。如果外面也打不开,或者时好时坏,那才是服务器的问题。
这一步能帮你省掉一半的无效排查时间。
第三步:看监控——先看仪表盘
如果你装了监控(比如Netdata),现在打开它。
一眼看过去:
- CPU是不是满了?哪个核?
- 内存用光了?SWAP是不是在大量换入换出?
- 磁盘是不是满了?IO等待(%wa)高不高?
- 网络是不是被打满了?
监控的厉害之处在于,它能告诉你“哪里不正常”,而不是让你漫无目的地猜。
真实案例:有次一个朋友说网站慢,我让他打开Netdata,一眼看到磁盘IO等待异常高。再查,发现是MySQL在疯狂写日志。原来他开了general_log忘了关。
如果没装监控,你现在需要马上装一个。以后就不用盲人摸象了。
第四步:查日志——服务器自己会告诉你
服务器会把所有问题写进日志。你要做的就是去翻。
Web日志:Nginx的access.log和error.log。access.log看状态码,如果一堆500、502,那就是后端有问题。error.log看具体报错。
系统日志:/var/log/messages 或 /var/log/syslog。看有没有硬件错误、内核报错、OOM(内存溢出)杀进程的记录。
数据库日志:MySQL的error.log。看是不是连接数爆了、是不是死锁了。
应用日志:你自己部署的程序写的日志。看有没有异常堆栈。
用 tail -100 看最后100行,用 grep error 快速定位。
反常识点:很多人的日志只写不读。日志是服务器写给你的信,你不看,它白写。
第五步:用命令行深挖——找到元凶
日志告诉你“发生了什么”,命令行告诉你“谁干的”。
CPU高:
top看哪个进程占CPU。按P排序。- 如果进程是应用,可能是代码有问题。
- 如果进程是系统(如ksoftirqd),可能是网络中断太多。
内存高:
free -h看总量和SWAP使用。smem看每个进程的真实内存占用(比top准)。- 如果SWAP在用,说明内存不够了。
磁盘满:
df -h看哪个分区满了。du -sh /* | sort -hr | head -20找大目录。- 通常是日志没切分,或者某个程序在疯狂写文件。
网络异常:
netstat -an | grep :80 | wc -l看连接数。ss -tunap看连接状态,TIME_WAIT太多说明短连接多,ESTABLISHED太多可能被攻击。iftop看实时流量。
第六步:定位根因——不是症状,是原因
这一步最难,也最重要。
症状是“CPU高”,原因是“代码死循环”。症状是“502”,原因是“PHP-FPM进程不够”。症状是“磁盘满”,原因是“日志没轮转”。
怎么从症状找到原因?
- 如果是CPU高,看是哪个进程,再看它在干什么(
strace -p 进程ID)。 - 如果是502,查Nginx error.log看是连不上谁,再去查那个服务(PHP-FPM、MySQL)的日志。
- 如果是磁盘满,找到大文件,看内容,判断是谁写的。
真实案例:有一次CPU持续100%,top看到是mysqld。mysqladmin processlist发现大量SELECT ... FOR UPDATE,都是同一个表。开发说他们刚上线了一个新功能,每次请求都会锁表。回滚代码,问题解决。
如果只重启MySQL,过一会儿还会爆。找到根因才能根治。
第七步:修复并验证——然后记下来
找到原因之后,动手修复:
- 改配置?改完重启服务。
- 回滚代码?回滚后验证。
- 加资源?加上去再看监控。
- 封IP?封完确认攻击停了。
修复之后,验证问题是否解决。刷新页面,看监控指标是否恢复正常,跑一下压测确认稳定。
然后,最重要的一步:记下来。
写个简单的记录:什么时间、什么现象、什么原因、怎么解决的。下次遇到类似问题,翻出来就能快速定位。不用再从头查一遍。
这套流程的核心不是技术,是顺序
很多人排查问题,第一步就是登录服务器敲命令,东敲一下西敲一下,越敲越乱。
真正的顺序应该是:
- 确认现象
- 缩小范围
- 看监控
- 查日志
- 深挖
- 定位根因
- 修复记录
前三步不用登录服务器。第四步开始登录。第五步是深挖。第六步是动脑子。第七步是收尾。
这套顺序能帮你节省大量时间,也能避免在错误的方向上浪费精力。
最后送你一句话
我第一任领导教我的:“不要带着情绪修服务器。先停下来,想清楚再动手。”
服务器出问题的时候,人会急,会慌,会想尽快“搞定”。但急的时候最容易出错,错上加错。
所以下次服务器闹脾气,先深呼吸,按这7步走一遍。你会发现,大多数问题其实没那么难,只是你以前没找到对的路。