

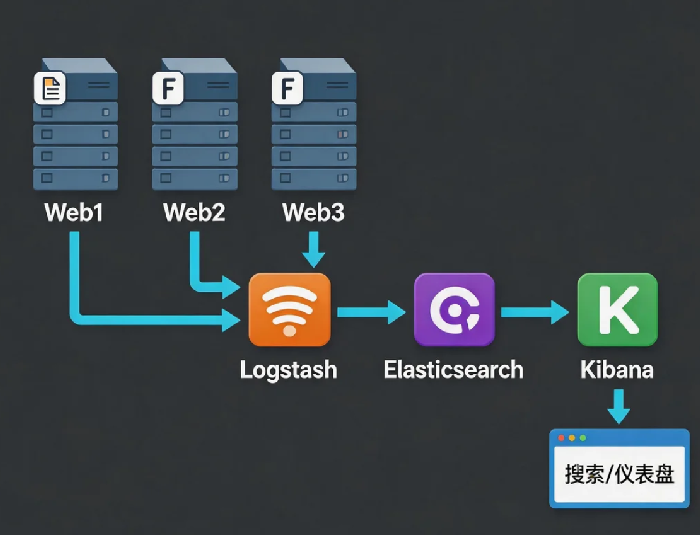
你有几台服务器?两台,还是十台?
当你想查一个问题,比如“昨天下午3点502错误是哪个请求导致的”,你要一台一台登录,翻日志,grep关键词。A服务器没有,去B服务器,B没有去C。等全部查完,半小时过去了。
如果有十台服务器,查一次错误等于加班一次。
ELK Stack就是解决这个问题的。把分散在多台服务器上的日志,统一收集到一个中心,在一个界面里搜索、过滤、看图。今天带你用Docker Compose极简部署一套ELK,让你告别一台台翻日志的日子。
先看一个数据
某公司运维团队,以前排查一次故障平均耗时40分钟(10台服务器)。用ELK集中日志后,平均耗时降到8分钟。效率提升500%。
不是他们变聪明了,是搜索日志从一个一个文件里grep,变成了在一个输入框里敲关键词。
ELK是什么?
ELK是三个开源项目的缩写:
- E (Elasticsearch):搜索引擎,负责存储和索引日志,让你能毫秒级搜索。
- L (Logstash):日志采集管道,从服务器拉日志,解析、过滤、发往Elasticsearch。
- K (Kibana):可视化界面,搜索、图表、仪表盘都在这里操作。
日志的流动方向:你的服务器(日志文件)→ Logstash → Elasticsearch → Kibana。
你只需要在浏览器打开Kibana,剩下的就是敲搜索词。
极简部署(Docker Compose)
ELK组件多,分别安装很麻烦。Docker Compose能让所有组件一键启动。
第一步:安装Docker和Docker Compose
bash
# 安装Docker curl -fsSL https://get.docker.com | bash # 安装Docker Compose curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose
第二步:创建docker-compose.yml
yaml
version: '3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.11.0
environment:
- discovery.type=single-node
- xpack.security.enabled=false
ports:
- "9200:9200"
volumes:
- es_data:/usr/share/elasticsearch/data
logstash:
image: docker.elastic.co/logstash/logstash:8.11.0
volumes:
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
ports:
- "5044:5044"
depends_on:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.11.0
ports:
- "5601:5601"
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
depends_on:
- elasticsearch
volumes:
es_data:
第三步:配置Logstash
创建logstash.conf文件,定义从哪里读日志、发到哪里去。
ruby
input {
# 从TCP端口接收日志(Filebeat或nc发送)
tcp {
port => 5044
codec => json_lines
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "app-logs-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}
第四步:启动ELK
bash
docker-compose up -d
等待几分钟(首次启动会拉取镜像)。访问http://你的服务器IP:5601,看到Kibana界面,说明部署成功。
收集服务器日志
ELK跑起来了,怎么把日志送进去?两种主流方式:
方式一:Filebeat(推荐)
在被监控的服务器上安装Filebeat,配置输出到ELK。
bash
# 安装Filebeat curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.11.0-amd64.deb dpkg -i filebeat-8.11.0-amd64.deb
配置/etc/filebeat/filebeat.yml:
yaml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
output.logstash:
hosts: ["ELK服务器IP:5044"]
启动:
bash
systemctl start filebeat
方式二:nc命令行(临时测试)
如果你只想临时发送一条日志测试:
bash
echo '{"message":"test log", "app":"myapp"}' | nc ELK服务器IP 5044
在Kibana里搜索日志
打开http://ELK服务器IP:5601。
第一步:创建索引模式。点击“Management”→“Stack Management”→“Index Patterns”→“Create index pattern”,输入app-logs-*,下一步,选择@timestamp作为时间字段。
第二步:进入“Discover”页面。你会看到所有收集到的日志列表。上方搜索框可以输入关键词,比如"502"或"error"。右侧时间筛选器可以只看最近15分钟、1小时或自定义时间范围。
常用搜索语法:
message: "502":搜索包含502的日志host: "web01" AND level: "ERROR":web01服务器上的错误日志response_time: > 1000:响应时间超过1秒的请求
创建仪表盘:在“Dashboard”页面,可以把常用搜索保存成图表,比如“过去24小时各服务器错误日志数量”,一打开就能看到全局状况。
进阶:通过Nginx日志监控网站状态
一个简单的仪表盘可以包含:
- 每分钟请求数(折线图)
- HTTP状态码分布(饼图,200/404/500/502占比)
- 最慢的10个URL(数据表)
- 错误日志数量趋势(面积图)
这些图表不需要写代码,在Kibana的可视化界面里点几下就能配。
资源规划
- 小规模(3-5台服务器,每天1GB日志):2核4GB,足够。
- 中等规模(10-20台服务器,每天10GB日志):4核8GB,考虑增加磁盘。
- Elasticsearch很吃内存,至少分配2GB给JVM。调整方式是设置环境变量
ES_JAVA_OPTS="-Xms2g -Xmx2g"。
磁盘按日均日志量×保留天数×1.5估算。保留7天的话,每天1GB日志大约需要11GB磁盘。
一个真实案例
有个公司,后端服务跑在6台服务器上。每次用户报“系统错误”,运维要登录所有服务器grep日志,找到报错时间段的记录。有时候查不出原因,因为日志不在同一台机器上。
用ELK集中日志后,运维在Kibana里输入"ERROR" AND "PaymentService",所有服务器的错误日志排在一起,时间线一目了然。之前半小时的排查,现在不到1分钟。
技术总监说:“ELK不是监控工具,是运维的搜索引擎。”
最后一句
ELK的部署不复杂,Docker Compose一键启动,Filebeat配置一下,你的日志就开始汇聚了。
有了集中日志,排查问题不再需要一台台连服务器。你只需要打开Kibana,敲几个关键词,答案就出来了。
从今天开始,把分散在各处的日志聚到一起。你会发现,以前让你头疼的排查工作,变得像用Google一样简单。