

你的网站用户越来越多,数据库查询越来越慢。你看监控,CPU不高,内存够用,磁盘不忙。但数据库就是慢。因为读太多了。一张热门文章表,每秒被查询几百次。每次查询都走数据库,再好的硬件也扛不住。
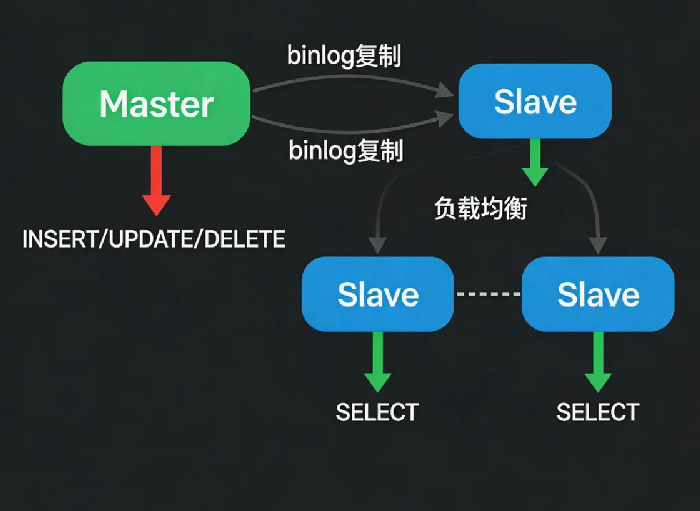
解决办法:一主多从,读写分离。主库负责写,从库负责读。读请求分散到多个从库,主库压力骤降。
今天搭一个最简单的主从复制。生产环境再加中间件或配置多从库,原理是一样的。
先看一个数据
某资讯网站,日活10万,数据库读写在同一个库。高峰期CPU经常80%以上。做了主从复制 + 读写分离后,主库CPU降到30%,从库CPU 50%。读请求全部被从库扛住,主库只需要处理写入。
数据库的瓶颈,往往是读,不是写。
主从复制原理
主从复制做的事:主库把数据变更记录到二进制日志(binlog),从库把主库的binlog拉过来,在自己这里重放一遍。最终主库和从库数据一致。
三个线程:
- 主库:
Binlog Dump线程,发送binlog给从库 - 从库:
I/O线程,连主库收binlog,写入中继日志(relay log) - 从库:
SQL线程,读中继日志,重放SQL
主库宕机了,从库还有一份数据。虽然不能自动切换,但至少数据没丢,可以手动把业务切到从库。
环境准备
两台服务器,都装好MySQL:
- 主库:192.168.1.10
- 从库:192.168.1.20
确保两台能互通,防火墙开放3306端口。
第一步:配置主库
编辑/etc/mysql/my.cnf或/etc/my.cnf:
ini
[mysqld] server-id = 1 log_bin = /var/log/mysql/mysql-bin.log binlog_format = ROW binlog_do_db = myapp
重启主库MySQL。
创建一个专门用于复制的用户:
sql
CREATE USER 'replicator'@'%' IDENTIFIED BY 'strong_password'; GRANT REPLICATION SLAVE ON *.* TO 'replicator'@'%'; FLUSH PRIVILEGES;
查看主库状态,记下binlog文件名和位置:
sql
SHOW MASTER STATUS;
输出类似:
text
+------------------+----------+ | File | Position | +------------------+----------+ | mysql-bin.000001 | 1234567 | +------------------+----------+
记下来,后面配置从库要用。
第二步:配置从库
编辑从库配置文件:
ini
[mysqld] server-id = 2 relay_log = /var/log/mysql/mysql-relay-bin.log read_only = 1
read_only = 1让从库只读,防止有人在从库上写数据导致主从不一致。重启从库MySQL。
第三步:把主库数据同步到从库
如果主库已经有数据,需要先同步。否则从库缺了数据,复制会报错。
方法:主库导出数据,传到从库导入。
bash
# 主库导出(不锁表,InnoDB用--single-transaction) mysqldump --single-transaction --master-data=2 --databases myapp > myapp.sql # 传到从库 scp myapp.sql root@192.168.1.20:/root/ # 从库导入 mysql -u root -p < /root/myapp.sql
第四步:配置从库复制
在从库MySQL里执行:
sql
CHANGE MASTER TO MASTER_HOST='192.168.1.10', MASTER_USER='replicator', MASTER_PASSWORD='strong_password', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=1234567;
MASTER_LOG_FILE和MASTER_LOG_POS填之前SHOW MASTER STATUS记下的值。启动复制:
sql
START SLAVE;
查看复制状态:
sql
SHOW SLAVE STATUS\G
重点关注:
Slave_IO_Running: YesSlave_SQL_Running: Yes
两个都是Yes,复制正常。任何一个不是Yes,看Last_Error字段排查。
测试主从复制
在主库上创建一个测试表:
sql
USE myapp; CREATE TABLE test_replica (id INT, name VARCHAR(50)); INSERT INTO test_replica VALUES (1, 'hello');
去从库查询:
sql
USE myapp; SELECT * FROM test_replica;
如果能查到数据,主从复制成功。
读写分离:代码层面的改造
主从搭好了,怎么让写请求走主库、读请求走从库?
方案一:应用层判断(推荐)
在代码里区分读写。以PHP为例:
php
// 写操作(INSERT、UPDATE、DELETE)走主库
$db_master = new PDO('mysql:host=192.168.1.10;dbname=myapp', $user, $pass);
// 读操作(SELECT)走从库
$db_slave = new PDO('mysql:host=192.168.1.20;dbname=myapp', $user, $pass);
方案二:中间件代理
使用MySQL Proxy、ProxySQL、MaxScale等工具,自动识别SQL类型并路由。优点是不用改代码。缺点是多了个组件,增加了运维复杂度。
小项目用方案一,简单可控。大项目用方案二,统一管理。
监控主从延迟
从库和主库之间有时延。主库写入了,从库要过几秒才能看到。监控延迟:
sql
SHOW SLAVE STATUS\G
看Seconds_Behind_Master。0表示无延迟。数字持续增大,说明从库跟不上主库的写入速度。
延迟原因:
- 从库配置太低(CPU/内存不够)
- 主库写入量太大
- 从库在执行大查询,阻塞了SQL线程
- 网络慢
解决办法:
- 升级从库配置
- 增加从库数量分担读请求
- 优化主库的大事务
- 把一些不重要的查询放到专门的从库
监控告警:Seconds_Behind_Master持续超过60秒,发告警。
出错了怎么办
跳过单个错误(知道为什么错且不影响一致性):
sql
STOP SLAVE; SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; START SLAVE;
重新搭建从库:数据差异太大,直接重做。重新导入主库数据,重新CHANGE MASTER TO,重新START SLAVE。
主库宕机:手动把写请求切到从库,提升从库为主库。生产环境需要配合高可用方案(MHA、Orchestrator)实现自动切换。
真实案例
一个电商网站,高峰期数据库CPU经常100%。做了主从复制 + 读写分离,把商品查询、订单查询全部走从库,主库只处理下单、支付等写操作。主库CPU降到40%,网站响应时间从2秒降到0.5秒。从库配了两台,一台挂了,另一台还能顶。再也没有因为数据库压力导致网站卡顿。
负责人说:“原来瓶颈一直在读,不是写。”
最后一句
主从复制不难,几行配置的事。读写分离也不难,代码里区分一下连接。
难的是下定决心去做。很多人觉得“现在还能扛”,就一直扛着,直到扛不住的那天。
如果你的数据库读压力已经让你睡不着觉,今天就把主从搭起来。主库写,从库读,压力分散。
你不欠数据库一个从库,你欠自己的睡眠一个交代。