

凌晨两点,手机狂震。监控告警:服务器离线。你打开电脑,心跳加速。脑子一片空白——先看什么?先重启吗?要不要叫别人?用户已经在骂了。
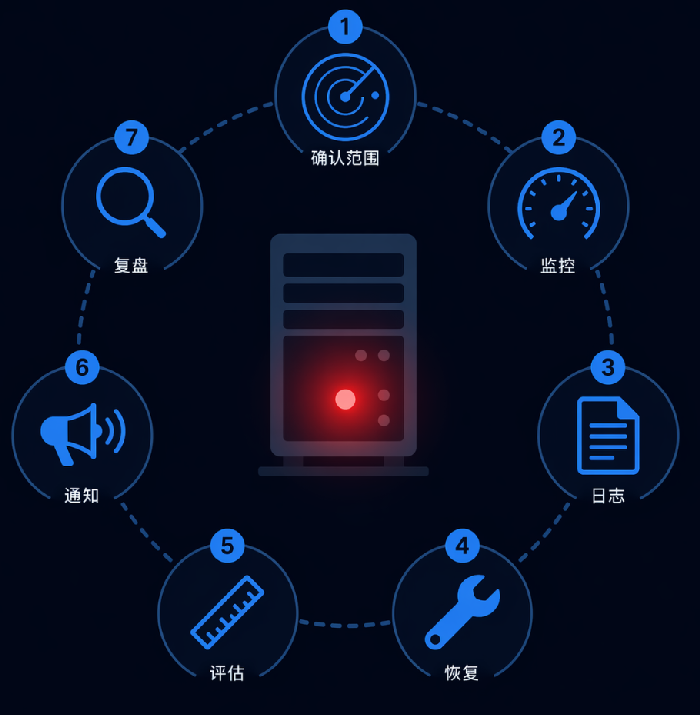
宕机的时候,最怕的不是技术难题,是脑子乱了。乱操作可能让问题更严重。今天给你一套标准流程,按顺序做,不会错。
先看一个数据
某云厂商统计,超过40%的宕机事件,恢复时间超过30分钟。其中一半的延迟,不是因为故障本身复杂,而是因为处理流程混乱。有人先重启,有人先看日志,有人到处问,没人做决定。
宕机不可怕,乱来才可怕。
第一步:确认范围
别急着登服务器。先搞清楚:是只有你一个人打不开,还是所有人都打不开?只有一台服务器挂了,还是整个业务都挂了?
怎么确认:
- 用手机网络访问网站(不要用公司WiFi,可能是公司网络问题)
- 问同事:“你能打开吗?”
- 看监控:是一台机器掉线,还是所有机器都掉线
如果是只有你自己打不开,问题可能在你本地(DNS、公司网络)。如果是多台服务器同时挂,可能是机房间断网、云厂商故障、或上游服务挂了。
这一步30秒完成。 不确认范围就冲进服务器,可能你忙半天,发现是DNS解析错了。
第二步:看监控
确认是服务器问题后,打开监控面板(Netdata、云监控、Prometheus)。
看什么:
- CPU是突然飙升还是一直高?
- 内存是不是满了?
- 磁盘IO有没有异常?
- 网络流量有没有被打满?
- 磁盘满了没有?
大多数故障,监控一眼就能看出问题。磁盘满了、CPU被挖矿占满、带宽被打爆——都直接显示在监控上。
这一步1分钟完成。
第三步:查日志
监控没发现问题,或者监控也挂了,登服务器查日志。
先看系统日志:
bash
tail -100 /var/log/syslog tail -100 /var/log/messages
再看服务日志:
- Nginx:
/var/log/nginx/error.log - MySQL:
/var/log/mysql/error.log - PHP-FPM:
/var/log/php-fpm/error.log
找什么:
- OOM(内存不足,进程被杀)
- kernel panic(内核崩溃)
- segfault(程序崩溃)
- disk full(磁盘满)
- timeout(超时)
这一步2分钟。 日志通常会直接告诉你原因。如果什么都没找到,继续下一步。
第四步:尝试恢复
根据监控和日志的发现,尝试恢复。
常见情况的恢复操作:
| 问题 | 恢复操作 |
|---|---|
| 磁盘满了 | 清理日志、旧备份、临时文件 |
| CPU 100%(被挖矿) | kill进程、删定时任务、改密码 |
| 内存不足 | 重启服务、加swap(临时)、计划升级内存 |
| 服务挂了 | systemctl restart 服务 |
| 网络不通 | 检查安全组、防火墙、网卡状态 |
| 系统无响应 | 尝试SSH,连不上则去云控制台重启 |
不确定原因:按顺序重启:先重启服务,不行再重启服务器。
重启服务器前先通知用户。在官网放个公告“系统维护中”,或者直接挂维护页面。
这一步3分钟。
第五步:评估影响
恢复服务后,评估一下影响范围。
- 宕机多长时间?
- 影响了多少用户?
- 有没有数据丢失?
- 其他服务有没有受影响?
把时间和范围记下来。管理层会问,复盘需要。
这一步1分钟。
第六步:通知用户
服务恢复后,第一时间通知用户。不要等用户自己发现。
- 发公告:官网、微博、公众号
- 发群通知:客户群、内部群
- 写状态页:如果有的话更新一下
通知内容:
- 出问题的时间段
- 影响范围
- 已恢复
- 致歉
这一步1分钟。
第七步:事后复盘
不是宕机恢复了就完事了。没找到根因,下次还会挂。
复盘内容:
- 什么原因导致的?
- 为什么没提前发现?
- 监控为什么没告警?
- 恢复时间为什么这么长?
- 下次怎么更快恢复?
得出行动项:
- 加监控告警
- 写应急预案
- 改代码/配置
- 定期演练
这一步宕机后一周内完成。
宕机时的常见错误
错误一:不确认范围直接重启
明明是网络问题,你把服务器重启了。网络恢复了,你的服务也断了。
错误二:不通知用户就操作
你重启了,用户看到503。如果提前公告“维护5分钟”,用户能接受。
错误三:一个人闷头搞
半小时了还没恢复,也不叫人。早点叫同事,可能10分钟就解决了。
错误四:恢复了就不复盘
同样的坑,下次还会踩。
一个真实案例
某电商网站大促期间宕机。第一反应是“服务器挂了”,运维直接重启。重启后还是慢。后来发现是带宽被打满了——用户量太大。临时扩容带宽后恢复。
复盘时发现:监控告警配了,但没人看。如果提前看到带宽告警,不用重启,直接扩容。
后来他们把监控告警接到钉钉群,带宽超过80%就发消息。再也没发生过类似问题。
最后一句
宕机不可怕,可怕的是没有预案。
把这篇存下来,或者打印出来贴在工位。下次手机响了,按步骤走:确认范围→看监控→查日志→尝试恢复→评估影响→通知用户→事后复盘。
每一步该做什么,都写清楚了。照着做,不会乱。
宕机是迟早的事。你要做的不是“永远不挂”,是“挂了能快速恢复”。快到你用户还没发现,你已经修好了。