

服务器运行的稳定性直接影响网站、业务系统或API服务的可用性。而性能监控不仅是保障正常运行的手段,更是提前预警瓶颈、识别异常、支持扩容与故障定位的基础。本文将逐一解读服务器中必须重点监控的四大核心指标:CPU、内存、磁盘IO、网络,并结合实战说明其意义与采集方式。
一、为什么需要性能监控?
1. 提前发现性能瓶颈
- CPU高负载可能意味着进程无限循环、请求量过大或恶意攻击
- 磁盘IO飙升可能暗示数据库慢查询或日志暴增
2. 提供扩容/优化依据
- 数据量增大、用户数增加,是否需升级配置?性能趋势是关键依据
3. 故障快速定位
- 网站响应慢?是网络延迟、磁盘堵塞还是CPU飙升?通过监控定位问题源头
4. 支持报警机制
- 配合监控系统(如Zabbix、Prometheus)配置阈值自动告警
二、关键性能指标详解
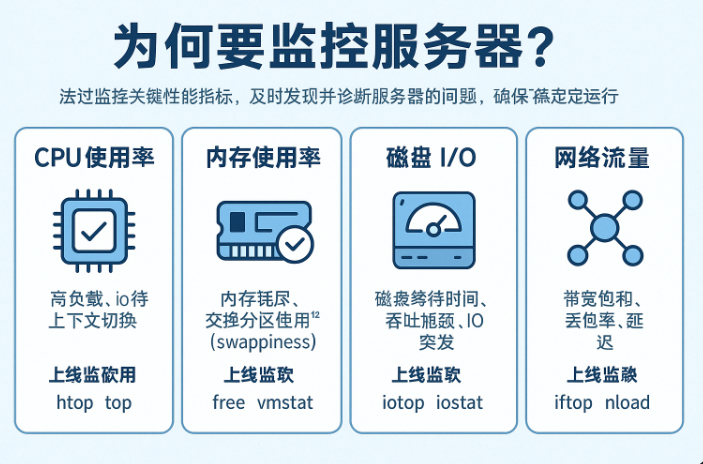
✅ CPU使用率(Usage)
- 含义:进程对CPU的利用率
- 关注点:user(用户进程)、system(内核进程)、iowait(等待磁盘IO)
- 过高表现:应用卡顿、响应延迟、系统负载升高
- 判断标准:
- 正常峰值 < 70%
- iowait > 10% 需重点排查磁盘瓶颈
监控命令:top、mpstat -P ALL、Prometheus + node_exporter
✅ 内存使用率(Memory)
- 含义:实际可用内存 vs 总内存占比(排除缓存)
- 关注点:used(实际占用)、buffers/cached(可释放缓存)
- 常见误解:Linux 内存“占满”是正常现象,关键看 swap 是否频繁使用
- 判断标准:
- free + buffers + cached < 15% => 存在内存紧张风险
- swap usage 增长 = 内存不够
监控命令:free -m、vmstat、htop
✅ 磁盘IO(IOPS/吞吐/延迟)
- 含义:磁盘每秒处理的读写次数、速率和响应时延
- 关注点:
- r/s, w/s(读写次数)
- await(IO延迟,> 20ms 需关注)
- util(磁盘利用率,> 80% 可视为瓶颈)
- 问题表现:数据库慢查询、系统卡顿、日志堆积
监控命令:iostat -x 1、iotop、Zabbix模板磁盘性能
✅ 网络流量与连接数
- 含义:服务器网卡上传/下载速率及TCP连接状况
- 关注点:
- 接收/发送速率(MB/s)
- TCP连接数(ESTABLISHED / TIME_WAIT)
- 丢包率、延迟(使用ping/traceroute测试)
- 问题表现:网站加载慢、连接失败、502网关超时
监控命令:iftop、nload、ss -s、netstat -anp
三、如何搭建服务器监控体系?
| 方案 | 说明 |
|---|---|
| Zabbix | 企业级开源监控平台,支持图表、告警、分组管理 |
| Prometheus + Grafana | 云原生组合,强大的时间序列与可视化能力 |
| Netdata | 开箱即用型实时可视化系统负载分析工具 |
| 自建Shell脚本 + cron | 适合小规模任务、快速部署监控日志收集 |
四、实践建议
- 不要只监控“平均值”,关注“最大值”和“瞬时峰值”
- 针对业务服务建立自定义指标(如API QPS、数据库连接数)
- 重要:性能指标监控 + 日志监控(Nginx/Mysql/syslog)结合使用,才能实现根因定位