

你有没有碰到过这样的窘境?
流量突然暴涨,服务器网络带宽瞬间打满,可是你设置的告警却一声不吭。你满头雾水地盯着面板,流量明明飙到了 100%,怎么监控系统还一脸“岁月静好”?然后,用户开始抱怨系统卡顿、接口超时、图片加载慢。你开始怀疑:我的监控系统到底有没有在工作?
别急,这种事发生得比你想象得还频繁。而且,大多数时候,问题并不出在系统没监控,而是你监控的方式不对、时机不对、对象不对。
今天我们就来聊聊一个被很多运维团队低估的问题:流量突发场景下,为什么服务器带宽打满却没有及时告警?我们又该如何有效限流、精准监控这些高风险场景?
带宽打满但监控“失联”?这事比你想象得常见
你以为监控系统能自动报警?以为设置一个“网卡使用率 > 90% 报警”就万无一失?
现实可没这么美好。
最常见的问题有以下几种:
1. 监控频率太低
很多系统设置的是 5 分钟或 1 分钟采样一次。这意味着什么?
意味着你错过了“那一波”——流量可能在 20 秒内就冲到顶,然后又降下来了,监控系统压根没赶上这班车。你以为一切正常,其实用户早就炸锅了。
2. 监控指标不够细颗粒度
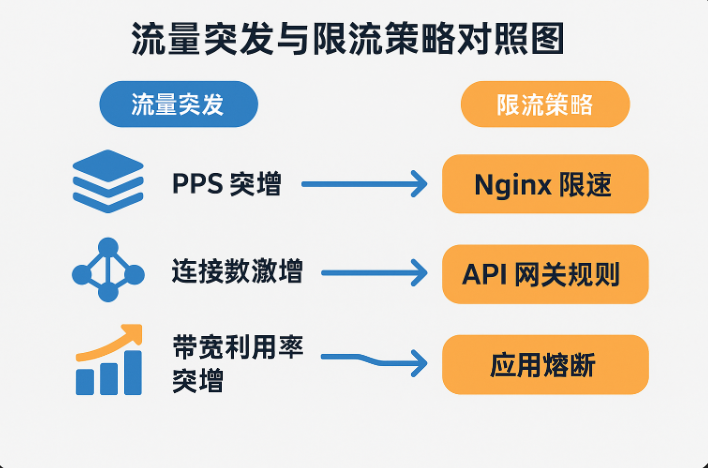
你可能监控的是“接口带宽利用率”,但没监控“瞬时 PPS(Packet Per Second)”或“端口突发流量”。
就像只看了车速,没看刹车距离;只看了 CPU 平均占用,没看 Load Average。
3. 没有抓住“突发”这个关键字
很多告警逻辑是基于“持续时间”的,比如“10 分钟内网卡流量超过 90% 就告警”。可流量突发就像闪电,来得快,走得也快——它根本不会等你 10 分钟,它要的就是一击致命。
为什么“突发流量”这么危险?
我们常说,高并发、高负载这些问题容易压垮系统。但你知道吗?突发流量比持续高负载更难防。
1. 它没有预兆
一个爬虫、一波营销推广、一次 API 被人恶意刷请求,甚至是 CDN 缓存穿透,流量就能瞬间暴涨。服务器来不及响应,网卡来不及排队,TCP 重传、丢包、连接阻塞,全套一起送上。
2. 它不只是带宽的问题
突发流量不是单纯地“跑满了网卡”,它可能会拖垮以下所有内容:
- 网络队列排满,触发丢包;
- 应用层超时、请求堆积;
- CPU 忽然负载飙高,触发系统 load alarm;
- 日志量突然爆炸,IO 被塞爆;
3. 它干掉的,是你的 SLA
你可能根本没意识到,突发流量哪怕只持续 1 分钟,都足以让用户请求失败 30%,页面打开失败率飙升。而用户不会关心你的带宽爆不爆,他只会说:“你这服务不稳定。”
如何精准监控突发带宽问题?
你要做的,不是靠“加带宽”解决问题,而是先看得清、感知准、反应快。
1. 设置秒级别采样
请把你的监控采样粒度从“分钟”级别降到“秒”级别,尤其是网络接口、带宽流量、PPS、BPS 指标。
如果你用的是 Prometheus,推荐加上:
yaml复制编辑scrape_interval: 5s
同时,设置 Alert Rule 时使用滑动窗口:
promQL复制编辑avg_over_time(node_network_receive_bytes_total[30s]) > 100000000
这样就能及时捕捉到那些 20 秒打满带宽的“闪电级”波动。
2. 关注 PPS 和连接数突变
突发流量不只是“总字节”上升那么简单,还可能表现为:
- TCP 连接数急剧增长(SYN Flood);
- 单 IP 请求量暴涨;
- 单个接口 PPS 突然增加。
这些都能用 iptables/conntrack、eBPF、或者 Netdata 来做高频数据采集与展示。
3. 黑盒探测:从用户视角评估延迟
你监控的再好,也可能漏掉“用户卡了但你不觉得”的情况。
推荐加一个黑盒探测组件,比如:
- curl 探测首页加载时间;
- httping 模拟用户请求;
- 定期从外部访问服务,记录响应时间波动。
只看“服务是否挂掉”不够,你得看“用户用起来爽不爽”。
有监控还不够,还得做限流与削峰
你发现问题没用,你得能扛住它。
突发流量要防,要控,要挡。
1. Nginx 层限速:不给你一次把我打爆的机会
用 Nginx 做流量限速其实很高效,哪怕前面接了 CDN,也可以做第二道防线:
nginx复制编辑limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;
limit_req zone=one burst=10 nodelay;
上面这段配置的意思是:每个 IP 每秒最多只能请求 5 次,最多能突发 10 次,然后就给你限流排队。
这就像地铁闸机:人太多时先拦一下,避免平台被挤爆。
2. 网关层限流:按用户、接口、服务维度定规则
如果你有 API 网关,比如 Kong、APISIX、Traefik 等,可以在入口层做限流,比如:
- 每个 token 每分钟最多 100 次;
- 某个接口每秒最多 2000 次;
- 某服务请求速率超限就返回 429;
别忘了加白名单,重要用户不能一刀切。
3. 内部应用也要自我保护
别总指望上层限流,应用自己也得“知道什么时候该说不”。
- 启用服务熔断:比如 Netflix 的 Hystrix、Sentinel;
- 实现请求速率监控与拒绝逻辑:自己把接口限住;
- 写日志的时候做缓冲+限速,避免日志 IO 把你拖垮;
针对不同场景的限流策略怎么选?
并不是所有流量都该挡。你得分清场景,选择合适的限流方式。
| 场景类型 | 建议策略 | 原因说明 |
|---|---|---|
| API 被刷 | IP 限速 + Token 限流 | 拦住异常请求 |
| 图片接口突发流量 | CDN + Nginx 限速 | 减轻源站压力 |
| 活动流量剧增 | 限流 + 弹性扩容 | 不限死,缓冲 |
| 日志量暴增 | 缓冲队列 + 日志切片 | 控制磁盘写入 |
不要盲目限,也不要放任不管。关键是:限该限的,放该放的。
那些你可能忽略的带宽问题
你以为自己只是“带宽被打满了”?
其实,还有一堆隐蔽的坑你可能完全没看到。
1. 虚拟化网卡 vs 物理网卡
你用的网卡到底是虚拟的还是直通的?KVM 虚拟机、Docker 容器用的是 veth,很多情况下你看到的数据只是容器内部视角,真实带宽可能打满了宿主机你都不知道。
建议使用 iftop、vnstat、ethtool 在宿主层观察。
2. QoS 没配置,某个进程吃光上行
服务器上跑了一个上传接口,结果它跑满了 100 Mbps,其他服务全卡死。为什么?你没做 QoS!
配置 Linux tc 命令、或者通过 iptables 配额,把上传/下载流量做分类管理,关键进程优先。
3. CDN 缓存穿透导致源站拉爆
你以为有 CDN 就没事?很多攻击和异常请求是“假请求”,直接导致 CDN 缓存失效,然后全部回源,把你的源站带宽拉满。
解决方法:
- 配置严格的缓存策略;
- 接入边缘 WAF,挡掉异常请求;
- 加日志分析,识别请求结构异常;
不只是防,更要会“弹”
你得接受一个现实:再强的限流,再快的响应,也抵不过业务突然的爆发。你防得住一次攻击,但不一定抗得住一次爆单。
所以,监控和限流是基础,但真正的生存之道是:弹性 + 自动化 + 快速响应能力。
- 用 K8s 自动扩容(HPA/VPA);
- 用异步处理机制削峰(消息队列、缓存预热);
- 做秒级告警 + 自愈策略(Prometheus + Alertmanager + webhook + 回滚);
别等系统崩了才出手,也别只盯着带宽图看热闹。
你需要的是一套完整的“抗压体系”。