

你的业务跑得再稳,CDN、WAF、K8s 全都拉满,如果 DNS 一出问题,照样“啪”一声全瘫。你可能花了数百万做多地容灾、多活架构、高可用网络,可最后因为一个 DNS 条目误删,全球用户都连不上来——听上去夸张?但这恰恰是真实世界最容易被忽视的一环。
DNS 就像网站的“门牌号”,可问题是,哪怕是一个数字写错、TTL 配置不当、权威解析挂掉,都能把你最核心的业务打回原形。最可怕的是,它出错时几乎无迹可寻,不像服务挂了会报 500,DNS 失效的用户看到的只是:网站打不开、连接超时、没反应……
所以,企业级 DNS 系统的容灾设计,必须从“看似简单”中看出“绝对不能错”的地方。今天这篇,我们就来好好扒一扒:为什么 DNS 这么容易成为全站瘫痪的元凶?而你又该怎么打造真正高可用的解析体系?
一次 DNS 配置错误,带来多大灾难?
先别谈理论,来一个真实故事。
一家头部互联网公司,在某次域名备案调整中,误将主业务域名的 NS 记录替换为错误值,结果数小时内全国各地用户陆续无法访问核心服务。你能想象这种“莫名其妙”却“无处下手”的恐怖感吗?运维查了 3 小时发现服务器都好着,最终才意识到:域名解析崩了。
更惨的是,DNS 是“缓存驱动型”的系统,哪怕你后来修复了错误,全网还要等 TTL 过期才能恢复——这波影响,谁都挡不住。
这只是最常见的几种问题之一,我们来系统性看看 DNS 出错的几大经典场景:
错误一:NS 记录配置错误或被篡改
当你的主域名 NS 记录被误改(甚至被劫持),整个解析路径就会指向一个不存在或恶意的权威服务器,用户再也找不到你的网站。
错误二:TTL 设置不当,导致缓存过久 or 失效过快
TTL 太高,出错后无法快速修复;
TTL 太低,权威服务器压力激增,容易打崩。
错误三:未设置备用解析线路或容灾线路
权威 DNS 服务器崩溃、机房断电、运营商劫持,这些都会导致你的域名“全网失联”。
错误四:配置变更流程不规范,无变更回滚能力
你是否有手动在域名解析面板里修改过记录?有没有人手抖删除了关键 CNAME?
DNS 为什么特别脆弱?
你或许觉得,DNS 不就是一个把域名解析成 IP 的服务吗?能有多复杂?
但你仔细想想,DNS 是所有互联网通信的“第一跳”。没有 DNS,你连 IP 都不知道,别说后端服务了。
而且,它的“弱点”恰恰在于它的设计理念:
1. DNS 是分布式但强依赖的系统
虽然 DNS 有递归、根域、权威、缓存等多个层级,但任何一个节点出现问题,最终都可能导致解析失败。而且没有服务 fallback!
2. 缓存机制带来“延迟修复”效应
DNS 本身依赖缓存来提升性能和减少查询量。但缓存意味着问题一旦产生,就不是“实时修复”的系统,TTL 没过期之前,用户就只能继续连错 IP。
3. 很多企业的 DNS 系统过于“静态”
你可能多年都没改动过 DNS 设置,导致配置陈旧、无备份、无监控、无防护——直到出问题那一刻,才意识到“哦,我都忘了我们还有个解析系统”。
企业级 DNS 容灾,怎么做才靠谱?
说白了,DNS 就像一扇门,你不能指望它永远不出错,但你必须设计好 出错了怎么办、多久能恢复、用户有没有备用通道可走。
我们从三个维度来拆解:
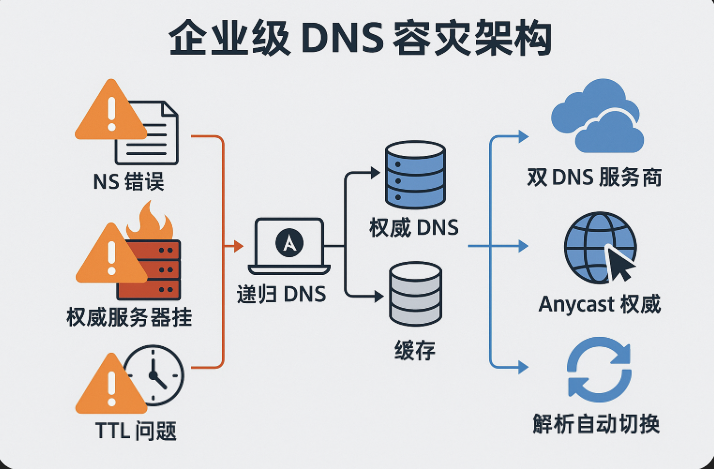
一、权威 DNS 服务器要“多、活、分布广”
企业 DNS 容灾的第一步,是让权威服务器具备高可用性和跨区域能力。
✅ 选择双 DNS 服务商(例如阿里云 + Cloudflare)
不要把鸡蛋放在一个篮子里。选择两个互不依赖的权威解析平台,并同步主域名的 NS 记录到两家。
注意:一定要同时配置 NS,不是主备,而是并行解析。
✅ 权威节点选支持 Anycast 的平台
Anycast 可以让全球用户就近访问最近的权威节点,延迟更低,抗攻击能力更强。如果你选的是传统单点权威 DNS,那么攻击者只需打挂这一个节点,你的全站就直接掉线。
✅ 使用具备 SLA 的商业 DNS 服务
免费的权威解析平台在稳定性、监控、通知上往往差很多。选带 SLA 的解析平台,不仅服务稳定,还能获取更强的日志分析、配置审核、DNSSEC 签名等高阶能力。
二、解析记录要“版本化+变更可审计”
人最怕的不是错,而是不知道自己做错了。
DNS 出错很大一部分原因是“操作不可控”。谁改了记录?改了什么?为什么没有审批?
✅ DNS 配置纳入 CI/CD 流程管理
你可以将 DNS 配置作为代码(IaC)管理,例如使用 Terraform 或脚本管理 DNS 记录,版本化、回滚、多人协作都变得安全有序。
✅ 设置修改审批流程 + 自动快照备份
不要让任何人随便进入解析面板就能改记录。配置审批流程,比如企业微信 / 邮件自动通知 + 审批。同时,每次变更都自动备份当前解析记录状态,方便回滚。
✅ 自动检测潜在配置风险
很多 DNS 服务商支持“智能校验”功能,比如提示你 NS 设置是否正确、TTL 是否过高、是否有死链 CNAME 等。
三、用户访问路径设计备用容灾方案
DNS 挂掉后,用户是否还有办法继续访问服务?有条件的话,你可以构建“智能回落机制”。
✅ 使用多域名+智能解析策略
假设你主域名是 example.com,你可以额外注册一个 example.cn、example.net 做为备用服务入口。
当主域名不可用时,客户端自动 fallback 到备用域名。例如 App 端通过配置 DNS over HTTPS + fallback 域名组合。
✅ 配合 CDN 做自定义回源容灾
很多 CDN 平台允许配置多源站,比如你主站挂了后,CDN 自动回源到次级 IP 或备用站点。结合权威 DNS 弹性策略,即使主记录挂掉,用户依然能访问缓存或临时备用资源。
✅ 针对重要用户设置固定 DNS 线路
VIP 客户、企业接口等,可以预先设置固定解析路径(如通过 HOSTS、DoH 地址、备用专线),不受公共 DNS 环境影响。
那 DNS 的监控呢?别再盯着“Ping 通”了!
DNS 出错时最尴尬的点就在于:很多人还在看服务器是否在线、接口是否返回 200,可 DNS 挂了,根本就没法访问你这些服务。
所以,DNS 的监控,必须“独立于业务服务监控之外”,具备以下特性:
✅ 从全球多个探测点定时解析测试
不要只看一个监控节点。要使用多个地理位置不同的节点测试域名是否能被成功解析,并比对 TTL、IP 地址是否一致。
✅ 配置 DNS 解析成功率报警阈值
比如:在任意 5 分钟内,来自任意 3 个探测点中 DNS 查询失败率 > 50%,立即告警。
✅ 检查 NS 解析路径是否发生变化
NS 劫持是高级攻击手段,务必监控 NS 记录是否被修改,以及返回权威解析节点是否符合预期。
✅ 建立服务依赖关系图谱
将 DNS 服务作为你监控系统中的独立节点,纳入全链路拓扑图,明确“DNS 崩了会影响哪些服务”,以便故障时更快定位。
最后,别再把 DNS 当“背景板”
很多人说,DNS 配置一次之后就不用动了。确实,它平时很少成为焦点,但一旦出问题,伤害巨大、恢复困难。
DNS 容灾的价值,在于它的 预防性——你做得好没人夸你,出一次错就可能进复盘会议。
别等用户反馈“打不开网站”了才意识到是 DNS 解析挂了,别等核心接口 5xx 飙升才发现 NS 配错了。
DNS 本身并不复杂,难的是你是否能把它当作“关键服务”去对待,设计出一套可见、可控、可恢复的体系。
让 DNS 真正高可用,不是靠“配置一次不动”,而是靠“时时盯、日日测、步步防”。