

有没有那么一瞬间,你盯着服务器公网 IP 发呆:明明服务部署在线上,页面却加载地像拨号时代;明明 Ping 是通的,但用户反馈“打不开”;明明带宽监控没报警,但海外访问全都卡成 PPT。
你是不是也有过这种错觉:“公网 IP 通了就代表服务是正常的”?可真相是,有时候 Ping 不等于可达,通了不代表好用。
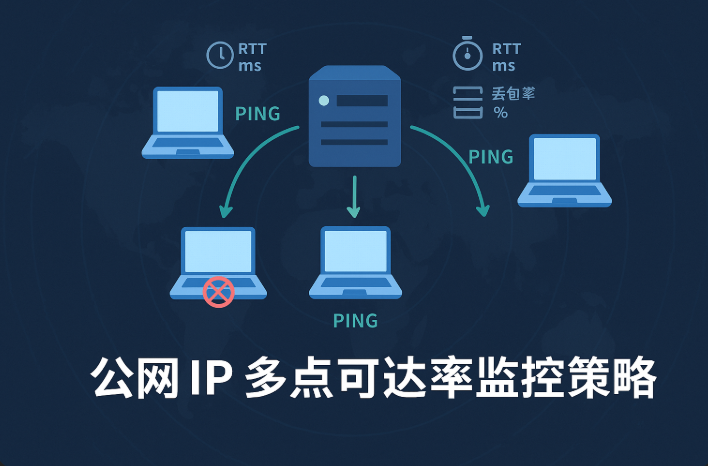
尤其是公网 IP 一旦被跨运营商、跨地域、多 NAT、多跳路由包围,一个入口的稳定,不代表整体体验就是稳定的。所以我们得换个姿势看问题:不是“通不通”,而是“多点是否都能通且好通”。
这篇文章,就带你从零搞懂多点 Ping 的策略逻辑,以及如何用它监控公网 IP 的真实可达率,给自己一个稳定访问的底气。
一、为什么单点 Ping 不靠谱?
你用 ping xxx.xxx.xxx.xxx,看到四个 reply:
python64 bytes from xxx.xxx.xxx.xxx: icmp_seq=1 ttl=51 time=23.4 ms
...
你松了一口气:“还活着”。但这只是从你当前设备出发的“局部视角”。
问题在于:
- 你可能是电信用户,而用户在联通、移动网络下访问同个 IP 就超时;
- 你可能是国内设备,国外用户访问则丢包 70%;
- 你可能走的是默认路由,别人经过高峰拥塞路径,延迟爆表;
也就是说,Ping 是“活着”,但未必“健康”。你看到的是“我能看到”,而不是“大家都能看到”。
二、公网 IP 的“假通”现象:为什么会误判健康状态?
公网 IP 有几个常见的“假通”场景:
- 智能防火墙或 CDN 自动限速:你自己能通,但 IP 在不同地域被限;
- 运营商路由差异:中国联通能通,中国移动绕海外;
- 出口线路不对称:请求出去没问题,回来的包走了别的方向,中途掉了;
- ICMP 策略控制:服务器开放了 ICMP 回应,但业务服务(HTTP/TCP)完全挂了;
换句话说,公网 IP 像个“看得见但摸不着”的幻影。你不能只凭一台机器说它好。
三、用“多点 Ping”构建真实可达性视角:从单点转向分布式
解决办法很简单却高效:多点探测。
什么叫多点 Ping?就是从不同的探测节点同时 Ping 同一个公网 IP,对比响应延迟、丢包率、跳数变化,形成多维度健康视图。
关键指标:
- RTT 延迟:不同地域的访问耗时;
- 丢包率:是否存在部分区域无法 Ping 通;
- 跳数 TTL:是否存在异常绕路;
- 探测路径变化频率:是否有 BGP 动荡或路由漂移;
通过这些数据,构建一张“真实用户视角”的网络健康图。
四、搭建自己的多点 Ping 系统:实战架构拆解
你可以用以下两种方式搭建:
方案一:自建轻量多点节点(推荐)
- 挑选几个地域(华北、华东、香港、洛杉矶、东京等);
- 在腾讯云、阿里云等购买轻量云(2 核 2G 配 5M 带宽即可);
- 每台机器部署
ping脚本 + cron 定时任务,或使用fping批量探测; - 将探测结果推送到一台统一采集服务器(可用 Prometheus + Pushgateway);
- 用 Grafana 可视化 + Alertmanager 做告警;
优势:灵活、成本可控、完全掌控。
方案二:使用现成的探测服务(低运维)
比如:
- 腾讯云「全球可用性探测」
- 阿里云「全局 Ping 服务」
- cloudflare Radar(免费可查跨国路径)
- 国外:RIPE Atlas(基于全球探针)
劣势:商业接口费可能偏贵、定制灵活性差。
五、数据分析:怎样判断“公网 IP 不稳定”?
你搭好了多点探测系统,下一步是分析数据。
常见判断逻辑:
| 指标 | 异常阈值 | 异常类型 |
|---|---|---|
| 单点丢包率 > 20% 且持续 5 分钟以上 | 是 | 单路径不通 |
| 多点平均延迟比历史基线高 30% | 是 | 拥塞 |
| 某一区域连续超时 10 次以上 | 是 | 局部故障 |
| Trace 路径变化频率异常高 | 是 | 路由漂移 |
| TTL 减少且跳数大幅增加 | 是 | 被绕路 |
触发报警的方式:
- 使用 Prometheus + Blackbox Exporter 每分钟探测;
- 定义自定义规则:如 3 个以上节点同时丢包,触发飞书 / 邮件告警;
- 设置时间窗逻辑(不是瞬时波动,而是连续波动才报警);
六、如何优化公网 IP 可达率?
发现问题之后,不解决就等于白监控。以下几个方向可以考虑:
1. 接入多运营商 BGP 回源
不靠单线路吃天下。选择 BGP 多线回源(如腾讯云 BGP EIP)确保不同地域路由走本地最优路径。
2. 使用智能调度的 CDN / Anycast 加速
利用 DNS 智能解析 + Anycast IP,将用户请求导入就近节点。
CDN 只适用于静态资源,但一些平台也支持 TCP 反向代理,可以加速公网 IP。
3. 多出口部署+健康路由切换
主出口异常自动切备线路。典型方法:
- keepalived + 双 ISP + BGP 路由权重
- 或者云平台本身支持的主备 IP(阿里云、腾讯云都有类似服务)
4. 更换劣质 IP 段
很多时候问题不是你的服务,而是你买的 IP 就“天生残疾”:被墙、被封、被限速。
腾讯云、阿里云的 IP 都分有质量等级,不妨观察被封邮件、告警频次、丢包率重新选择。
七、业务层的“多点可达率”采集方法(进阶)
Ping 是网络层的可达性,那应用层怎么做“多点访问可达率”?
简单说:从不同探测节点 curl 你的服务接口,收集 HTTP 状态码 + 返回时间 + 内容校验。
推荐工具:
curl + jq脚本配合 cron job;- 或者使用 Blackbox Exporter 的 HTTP 模式;
- 使用 Feishu/Bark/邮件通知异常节点;
你监控的是“用户访问结果”,而不是“基础网络指标”,两者要结合看才有结论。
八、实战案例:一个业务延迟暴涨的溯源流程
项目背景:客户反馈海外访问某站卡顿,Ping 无丢包但加载缓慢。
排查路径:
- 多点 Ping 发现美西节点丢包 50%;
- Trace 路径显示 ICMP 正常走直连,但 TCP 路由漂移绕了俄罗斯;
- curl 实际业务接口发现 HTTP 超时 30%;
- 查明出口 NAT 转发表炸了,导致连接被中间释放;
- 最终调整 NAT 参数 + 更换 BGP 回源线路,恢复稳定。
这就验证了:Ping 正常≠用户体验好,多点 + 多层才是真正稳定保障。
九、结语:公网 IP 的可达性,是连接用户的“空气质量”
我们常常以为“公网 IP 买了就完事了”,可现实里,那只是开了一道门。是否好用、是否稳定、是否全球通畅,才是你服务真正能不能活得好的关键。
用多点 Ping 策略,不是多此一举,而是:
- 给你一个全局视角:别再被单点盲区欺骗;
- 给你一个主动预警系统:别等用户投诉再醒;
- 给你一个持续可演进的网络保障体系:别把服务交给运气。
公网 IP 是一块地,你得派“巡逻员”天天去踩点,才知道这片地有没有塌陷、有没有偷工减料。
把公网 IP 的“健康图谱”画出来,是每个线上服务稳定运行的开始。