

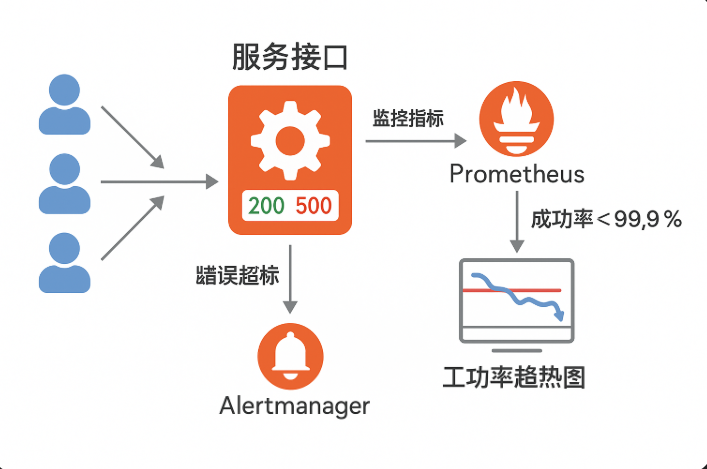
SRE 这个词大家早就听过了,可真的让你落地一个符合 SLI/SLO 体系的告警系统,哪怕只做“错误率”一个维度,大部分运维团队要么直接懵圈,要么搞成了“告警生成器”:不是告得太频就是全线沉默。
而现实业务里,“有没有问题”往往藏在告警之外。
你以为服务稳,是因为没有红色告警弹窗?用户已经三天不点按钮你都不知道——这也算“健康”?
搞 SLO 告警,不是因为“高级”,而是因为“传统方式太傻”。传统监控思路像是在盯着心电图曲线抖动:CPU波动了,报警;磁盘高了,报警;网卡爆了,报警。
SRE告诉我们一件事:你该关注的是用户体验,而不是系统表现。
所以今天我们只聊一件事:怎么用 Prometheus 做“错误率”相关的 SLI/SLO 告警体系。
不是讲概念,是手把手从“不会写 PromQL”开始,一步步带你搞定这件事。
你真的理解“错误率”了吗?
说“错误率告警”很容易,可你得先想清楚一个事:什么算“错”?
比如你设置了“接口5xx超过100就报警”,但你一天有1000万请求,这100个错误毛都不算;反过来,你某个接口一天才100次请求,错10次就是10%的错误率,不报警都对不起自己。
所以我们不是看“错误数”,是看“错误比例 + 时间 +趋势”。
而这,就涉及了 SLI(服务级别指标)和 SLO(服务级别目标)两个核心概念:
| 概念 | 含义 |
|---|---|
| SLI | 你如何衡量“服务是否正常”(如:成功率、响应时间) |
| SLO | 你期望 SLI 达到的目标(如:成功率 99.9%) |
| Error Budget | 容许的“出错额度” |
举个最简单的例子:
- 你每天有 10000 次请求
- SLO 设为成功率 ≥ 99.9%
- 那你一天最多允许 10 次错误
这就是你的 error budget。
超过这 10 次?你就该报警,而不是“等到 500 错误堆到几百再弹窗”。
步骤1:你的服务得先“能说话”
说到底,Prometheus 是个“拉型”系统,它只拉你暴露的 metrics。如果你的服务不会暴露 HTTP 请求状态码,它再聪明也抓不到你错没错。
示例1:Go 服务
用 promhttp 暴露一个指标路径:
gohttp.Handle("/metrics", promhttp.Handler())
添加中间件记录请求状态码:
gohttp_requests_total{status="200", handler="/api/login"}
http_requests_total{status="500", handler="/api/login"}
示例2:Nginx
用 nginx-exporter 把访问日志拆成 Prometheus 格式:
nginxlog_format prometheus '$request_method $status $uri ...';
然后你能拿到类似:
plaintextnginx_http_requests_total{status="2xx", server="api.xxx.com"}
注意:
- 一定要把
status和handler标签暴露出来 - 不然你后续 PromQL 没法聚合分析
步骤2:写出能代表 SLI 的 PromQL
我们先从“成功率”这个最简单的 SLI 开始写。
定义:
promql成功率 = 成功请求数 / 总请求数
如果你认为 5xx 是错误,那就:
promqlerror_rate = sum(rate(http_requests_total{status=~"5.."}[5m]))
/
sum(rate(http_requests_total[5m]))
这个表达式的意思是:
- 统计过去5分钟,错误率是多少
- 如果超过某个阈值(比如 0.001),就说明当前误差爆表了
步骤3:设计你的 SLO 阈值
SLO不是越高越好,很多团队一上来就写99.999%,结果告警24小时轮回一百遍。
合理的做法是:根据系统重要性,定义不同的 SLO:
| 服务类型 | SLO |
|---|---|
| 核心下单服务 | 99.95% |
| 内部管理后台 | 99.5% |
| 非关键查询API | 99.0% |
也就是说,你需要为每个 handler 单独做 SLO 区分。
步骤4:Prometheus 告警表达式怎么写?
好,假设你设定:
/api/login成功率 SLO 为 99.9%- 错误率超过 0.001 持续 2 分钟就报警
你可以写成:
yamlgroups:
- name: login-api
rules:
- alert: LoginErrorRateTooHigh
expr: |
(
sum(rate(http_requests_total{handler="/api/login",status=~"5.."}[1m]))
/
sum(rate(http_requests_total{handler="/api/login"}[1m]))
) > 0.001
for: 2m
labels:
severity: critical
annotations:
summary: "登录接口错误率超出 SLO"
description: "过去2分钟内,错误率大于0.1%"
你可以把 0.001 换成变量,从配置中心读取,也可以做多个级别(warning / critical)
步骤5:加入 Error Budget 的维度判断
上面的方式只是看“有没有错”,但更专业的方式,是看你有没有“超支”。
比如:
- 你一天最多容忍 100 次错
- 到了上午 10 点,错了 50 次
- 你就该预警了,因为你正以“爆预算”的速度在出错
这个判断需要做“累计值的速率预测”,可以结合 Grafana 里的 predict_linear() 函数:
promqlpredict_linear(error_total[1h], 12 * 3600) > error_budget
意思是:根据过去1小时错误速率,预测未来12小时是否会爆 budget。
步骤6:分接口设置策略(避免告警风暴)
一个大系统下,有几十个接口,每个都可能出错。如果你不分开处理,很容易变成“告警洪水”。
解决方式:
方式一:按 handler 聚合
promqlsum(rate(http_requests_total{status=~"5.."}[5m])) by (handler)
/
sum(rate(http_requests_total[5m])) by (handler)
这样可以分别为 /api/login、/api/pay、/api/userinfo 设置不同告警规则
方式二:添加调用量阈值过滤
有些接口一天才10个请求,错1次你就报警,不值得。
加一层判断:
promqlsum(rate(http_requests_total[5m])) by (handler) > 1
步骤7:用 Grafana 画出 SLI/SLO 视图
别让 PromQL 告警只出现在 Alertmanager 里,它得配合可视化,帮你:
- 展示整体成功率趋势
- 显示错误率排行榜
- 渲染 Error Budget 消耗曲线
推荐3个面板:
- SLI:成功率时间趋势 promql复制编辑
1 - (sum(rate(http_requests_total{status=~"5.."}[5m])) / sum(rate(http_requests_total[5m]))) - SLO:可视阈值折线图
- 在上图中加入水平线,如
y=0.999
- 在上图中加入水平线,如
- Error Budget Dashboard
- 显示每天还剩多少“出错额度”
附加玩法:Webhook 通知 + 自动静默窗口
别只让告警响,还要让它**“会说话”**。
你可以设置告警触发后自动:
- 生成工单
- 推送到飞书/Slack
- 标记当前版本
- 如果是部署窗口,自动静默30分钟,避免误告
yamlreceivers:
- name: 'slack-notifier'
slack_configs:
- channel: '#alerting'
text: |
*告警:* {{ .CommonLabels.alertname }}
*接口:* {{ .CommonLabels.handler }}
*错误率:* {{ .CommonAnnotations.description }}
一个成熟的错误率告警体系,长这样:
text[ 应用指标 ] → Prometheus → PromQL → SLI → SLO策略 → AlertManager → Grafana可视化 → 自动处理
你不再靠肉眼追日志,也不再靠经验设阈值,而是靠规则去管理、靠数据去追责。
你知道每次“出错”用了多少 error budget,知道哪个接口是“健康隐患”,知道现在的服务状态是否正在“烧预算”——这就是 SRE 的核心能力。
而 Prometheus,不是万能,但它是一把精确又强悍的刀。