

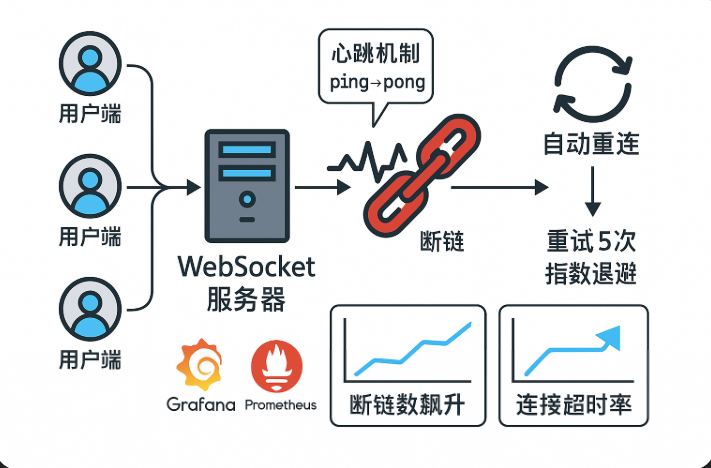
前一秒用户还在聊着天,后一秒界面突然“连接已断开,请重试”,你赶忙看日志,发现服务并没崩,CPU正常、内存平稳,也没报错。可用户就是断了,而且还不是一个两个。
这种时候你才想起来:这货不是 HTTP,是 WebSocket。它不是请求-响应那种你来我往,它像一根细长的管子,连上之后就一直开着,谁主动断谁才结束。可问题是——它,突然就没了。
WebSocket长连接的最大“魅力”,也正是它最大的隐患:它活得久,但死得不响。
在实际生产环境中,WebSocket连接的异常断开就像一只突然失联的无人机,看似飞得稳,实际上早就从系统“雷达”上消失了。你不主动检查,它永远挂着。你不主动处理,它会慢慢拖垮服务端资源。
这篇文章,我们就来彻底剖开这个麻烦的“连接永动机”:为什么 WebSocket 会突然断开?我们又该怎么第一时间发现它、处理它、重连它?整套流程你可以拎去就用,落地实操,帮你管好这些“不安分”的长连接。
WebSocket长连接,真的是你想的那么“稳定”吗?
我们先澄清一个误区:WebSocket 并不“稳定”,它只是“不显式断开”。
你建立了一个 WebSocket 连接,它不代表一定会持续在线。反而,它特别容易“悄悄”地断掉。
常见断开原因:
| 原因 | 说明 |
|---|---|
| 网络波动 | 移动端切网络、弱网波动,TCP 重连失败 |
| 中间层设备干预 | CDN、LB、代理服务器设置了最大空闲时间 |
| 服务端没有心跳策略 | 客户端断了你都不知道,连接还挂着 |
| 浏览器 / 客户端自动断链 | 网页失焦、App切后台,连接被系统杀死 |
| 异常错误未捕获 | 服务端 panic,或者客户端内存爆掉 |
有意思的是,大多数断开都不会主动报错,尤其是在服务端这边,你还以为用户在线,结果只是个 TCP Socket 占着茅坑不拉屎。
第一步:如何检测“连接已经断了”?
方法一:定时心跳机制(客户端 → 服务端)
这是最通用、也最有效的方式。客户端每隔 X 秒发送一条心跳消息(ping),服务器收到后回一条 pong,没收到就计时。如果连续几次都收不到,就断链。
客户端心跳示例(JavaScript):
jsconst socket = new WebSocket("wss://example.com/ws");
let heartbeatTimer;
function sendHeartbeat() {
if (socket.readyState === WebSocket.OPEN) {
socket.send(JSON.stringify({ type: "ping" }));
heartbeatTimer = setTimeout(() => {
console.warn("服务端未响应,准备重连");
reconnect();
}, 5000);
}
}
socket.onmessage = function(event) {
const data = JSON.parse(event.data);
if (data.type === "pong") {
clearTimeout(heartbeatTimer);
setTimeout(sendHeartbeat, 10000);
}
};
这个机制其实就是“假装聊天”,目的不是说话,而是知道你还活着。
方法二:服务端定时 ping(WebSocket 协议支持)
如果你用的是 Node.js、Go、Python WebSocket 框架,很多都支持服务端主动发 ping 帧:
jsws.ping()
配合监听 pong 响应,如果客户端没响应,就断开。
这个策略优点是服务端掌握主动权,缺点是移动端不一定响应得及时(特别是切后台时)。
方法三:连接 idle 检测(Nginx 或服务器)
如果你用 Nginx 反代 WebSocket,记得开启超时配置:
nginxproxy_read_timeout 60s;
proxy_send_timeout 60s;
否则客户端挂了你都不知道,Nginx 会一直保留连接。
第二步:发现断链之后怎么恢复?
最坑的一点不是“断了”,而是“你没感知到它断了”。
所以我们需要两件事:
- 客户端检测断开事件
- 触发自动重连流程
客户端断链监听(JavaScript):
jssocket.onclose = function(event) {
console.warn("连接关闭,状态码:" + event.code);
reconnect();
};
socket.onerror = function(event) {
console.error("连接出错:" + event.message);
socket.close();
};
自动重连逻辑:
- 重连前等待一定时间(指数回退)
- 最多尝试 N 次
- 每次尝试前先判断网络是否恢复(特别是移动端)
jslet retryCount = 0;
function reconnect() {
if (retryCount >= 5) {
alert("重连失败,请手动刷新页面");
return;
}
setTimeout(() => {
retryCount++;
initSocket();
}, Math.min(1000 * Math.pow(2, retryCount), 30000));
}
这样你至少不会让用户一直看着“断开”提示。
第三步:服务端怎么释放“假死连接”?
WebSocket 的隐性风险之一就是:服务端资源被“假死连接”占满。你以为是千人在线,实际一半是僵尸。
怎么判断谁是假死?
- 长时间没收到消息
- 没回应心跳
- TCP keepalive 失败
Node.js 服务端示例:
jssetInterval(() => {
wss.clients.forEach(client => {
if (!client.isAlive) return client.terminate();
client.isAlive = false;
client.ping();
});
}, 10000);
wss.on("connection", ws => {
ws.isAlive = true;
ws.on("pong", () => {
ws.isAlive = true;
});
});
这段代码的意思是:每10秒发一个 ping,如果 10 秒内收不到 pong,就断掉连接。
优化建议:
- 设置连接最大生命周期(如超过6小时就强制重连)
- 清理长期无操作连接
- 配合 Prometheus 指标收集连接数、心跳响应率
第四步:如何监控异常断链和连接数变化?
这时候就轮到 Prometheus 登场了。你可以暴露如下指标:
prometheuswebsocket_connection_total{state="connected"}
websocket_connection_drop_total{reason="timeout"}
websocket_reconnect_count
这些指标能帮你:
- 统计 WebSocket 连接总数
- 识别断链的类型(网络波动、服务崩溃、心跳超时)
- 告警连接断链高发
告警表达式示例:
promqlincrease(websocket_connection_drop_total[5m]) > 100
表示 5 分钟内断链超过 100 次,触发告警。
第五步:服务端重连策略与状态恢复
客户端断链重连之后,很多系统没有做状态恢复,结果用户看到的内容“突然清空”,聊天记录丢了、在线状态不对、房间ID失效……
你需要做“连接续约”机制:
- 客户端 reconnect 时携带旧连接ID
- 服务端从 Redis / 状态缓存中恢复上下文
- 如果恢复失败,重建连接上下文
json{
"type": "reconnect",
"session_id": "abc123",
"user_id": "42"
}
服务端判断 session 是否失效,如果还在,就把之前的订阅、上下文绑定回去。
第六步:如何避免被中间设备(LB/CDN)干掉连接?
很多 WebSocket 连接断开都不是客户端或服务端的问题,而是中间设备惹的祸:
- CDN 默认空闲超时 60s(阿里云、腾讯云都有)
- LB 设置最大连接保持时间
- ISP 运营商策略主动回收长连接
应对方法:
- 每30秒发一次心跳包(保持连接活跃)
- 使用TLS(wss://) 防止某些中间层窥探 WebSocket内容
- 配置 CDN/WebSocket 网关 的连接保持时间
例如阿里云 SLB:
bashset idle_timeout 300
第七步:如何通过 eBPF 捕获断链事件?
如果你是偏底层或高并发场景下部署 WebSocket,你可以用 eBPF 实时捕捉 socket 断链事件。
示例(使用 bpftrace):
bashbpftrace -e 'tracepoint:tcp:tcp_close { @[comm] = count(); }'
它能告诉你是哪个进程主动断开了 TCP,这对定位 WebSocket 闪断非常有用。
不要迷信“连接数”高就是活跃用户多
很多人喜欢在控制台展示“当前连接数”,仿佛这就是“在线用户数”,其实这完全错了。
你需要明确:
- 有效连接数 ≠ 活跃连接数
- 活跃连接数 ≠ 正常通信连接数
- 正常通信连接数 ≠ 不存在“假死连接”
真正有意义的,是:
prometheuswebsocket_connection_active_total
websocket_connection_stale_total
只有你定期清洗掉“假死连接”,再配合业务活跃行为,才能得出真实用户数据。
小结(我们不叫它结尾)
WebSocket 的魅力在于“实时”,但它的问题也藏在“持续”。你必须像照顾一条活水一样不断流动、监测、校验它,不然它一停,没人告诉你它停了。
靠它传消息,得先学会怎么确认它没死;靠它连用户,得先解决它自己掉线的问题。
连接不是永恒的,它是一个随时可能“假装还活着”的消耗体——而你要做的,就是想尽一切办法,第一时间知道它“装死了”,然后——让它活回来。