

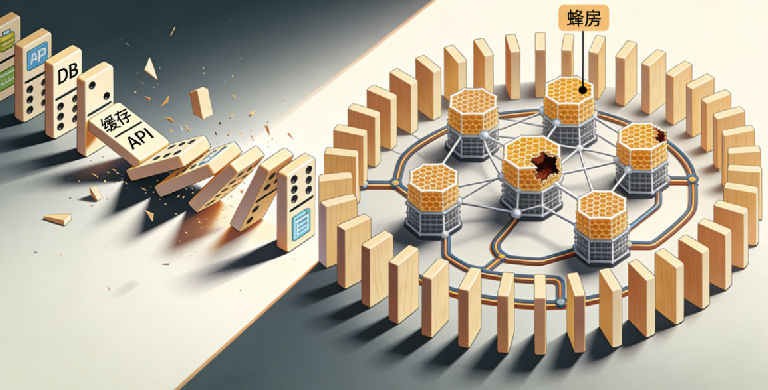
凌晨两点,某SaaS公司的CTO张远盯着监控屏幕上第12次变红的服务集群,意识到一个残酷的事实:他们的系统就像一个精心布置的骨牌阵——任何一张牌意外倒下,都会引发灾难性的连锁反应,而他们每个月平均要花超过10个小时来扶起这些骨牌。
01 瓷器店里的奔跑:我们曾经的“脆弱架构”
故事要从三年前说起。当时我们平台的月度服务可用性是99.6%,听起来不错?换算成时间,每月有近10个小时用户无法正常使用服务。更致命的是,这些故障就像无法预测的地震——数据库主从切换失败、缓存雪崩、某个第三方API超时拖垮整个支付链路。
我们的架构完美符合“脆弱系统”的所有特征:单体数据库、服务间紧耦合、关键路径无降级方案、故障恢复完全依赖人工排查。每次故障都像一次全员动员的消防演习,工程师们熬夜排查、回滚、重启,然后撰写根本原因分析报告,承诺“下次不会了”。
但下次总会以新的方式到来。
转折点发生在一个关键客户汇报会上。当客户CTO平静地问“你们的SLA是99.9%,但过去三个月平均只有99.4%,按照合同,我们应该获得服务积分”时,会议室空气突然凝固。那一刻我明白,架构韧性不是技术选修课,而是商业生存的必修课。
02 从追求“不死”到实现“速愈”:哲学的根本转变
我们做的第一个改变,不是技术,而是心态。我们放弃了追求“系统永远不死”的幻想——在复杂分布式系统中,这是不可能的。取而代之的是一个新的目标:当故障不可避免发生时,系统能多快自愈?
这个概念后来被称为“韧性系数”——衡量系统受冲击后恢复到正常状态的能力。我们开始跟踪两个新指标:平均检测时间(MTTD)和平均恢复时间(MTTR),而不仅仅是可用性百分比。
一个反直觉的洞见出现了:有时,故意让系统“小病不断”,反而能避免“大病一场”。我们开始实施“混沌工程”,在生产环境的非高峰时段,随机终止服务实例、模拟网络延迟、制造依赖故障。第一次实验时,团队紧张得手心出汗;三个月后,我们已能平静地看着一个区域服务中断,而用户毫无感知——因为流量已自动切换到健康区域。
03 韧性架构的四大支柱:我们如何重新搭建积木
真正的转变发生在架构层面。我们将过去的“骨牌阵”拆解,重新组装成具备韧性的“蜂窝结构”。这一过程围绕四个核心支柱展开:
第一支柱:冗余与隔离的辩证
我们首先实施的是故障域隔离。将用户数据按地理区域分片,确保任何一个数据中心故障只影响部分用户。接着,我们将单体数据库拆分为多个业务数据库,购物车、用户信息、订单系统各自独立。这样,一个系统的慢查询不会拖垮所有业务。
但冗余不是简单复制。我们采用了主动-主动多活部署,每个区域都能独立处理全部读写流量。这带来的额外好处是:用户无论身在何处,都能获得低延迟体验。
第二支柱:弹性与降级的艺术
我们引入了多层级的降级策略。当检测到支付网关响应时间超过阈值时,系统自动切换到“离线模式”——用户可提交订单,支付流程稍后异步处理。当库存服务不可用时,前端显示“库存计算中,请稍后再试”而非直接报错。
弹性伸缩也从简单的CPU阈值触发,升级为基于业务指标的预测性伸缩。通过分析历史数据,我们能在促销开始前30分钟自动扩容,而非等到系统已开始变慢。
第三支柱:可观测性驱动的智能自愈
我们在系统中植入了“神经系统”。分布式追踪让我们能看到每个请求的完整路径;结构化日志让我们能像查询数据库一样查询问题;指标系统实时计算数百个业务与技术指标。
更重要的是,我们建立了自动化故障响应手册。当数据库连接池使用率超过90%持续1分钟时,系统会自动执行预设动作:1) 扩容数据库代理;2) 临时限制低频查询;3) 通知值班工程师。大多数情况下,故障在用户感知前已被解决。
第四支柱:渐进式交付与快速回滚
我们彻底改变了发布流程。所有变更都通过特性开关控制,可随时启用或禁用。新功能先对内部用户开放,然后5%、10%、50%逐步放量。一旦错误率超过阈值,系统会在30秒内自动回滚至上一个健康版本。
这个能力在一次糟糕的数据库索引变更中救了我们。新索引导致查询性能下降70%,系统在检测到异常后45秒内自动禁用该变更,将影响控制在极小范围内。
04 数据背后的故事:那些令人惊讶的发现
在这一年的演进过程中,我们记录了一些反直觉的数据:
- 增加冗余反而降低了总成本:多活架构的额外硬件开销比预期低22%,因为我们可以利用不同区域的波峰波谷差异进行资源调度,总体资源利用率从35%提升到58%。
- 更频繁的部署带来更少的故障:当我们从每月一次大发布改为每周多次小发布后,与变更相关的故障率下降了67%。小批次变更更容易测试、监控和回滚。
- 自动化恢复比人工恢复更快且更可靠:自动化处理的故障平均恢复时间为2.3分钟,人工处理则需要17分钟。而且自动化恢复的一致性达99.8%,而人工处理中,不同工程师的操作差异可能导致不同结果。
最令人惊讶的是韧性投资的复合回报:在架构韧性上每投入1元,平均能避免3.2元的故障损失(包括客户赔偿、工程师加班、商誉损失等)。这是一项回报率极高的技术投资。
05 从架构韧性到组织韧性:最艰难的转变
技术架构的变革只完成了三分之一的工作。真正的挑战是将“韧性思维”融入组织的每一个细胞。
我们建立了跨职能的韧性委员会,每月召开会议审查系统弱点、分析故障模式、优化应急预案。开发团队开始在设计评审中加入“韧性问题”:这个服务失败时会怎样?如何降级?如何监控?
我们还引入了“错误预算”概念。每个季度,每个服务都有一定的“可故障时间”。只要不超预算,团队可以自由尝试创新。一旦预算快用完,就必须专注于稳定性改进。这巧妙平衡了创新与稳定之间的张力。
最困难也最重要的是改变故障文化。我们从“追责文化”转向“学习文化”。故障复盘会不再是为了找出“罪人”,而是为了理解系统的复杂性,发现改进机会。我们甚至设立了“最佳故障奖”,奖励那些揭示了系统深层次问题的事故分析。
06 写在最后:韧性不是终点,而是旅程
如今,我们的月度宕机时间已从10小时降至不足1小时,服务可用性稳定在99.99%以上。但比数字更重要的是,团队面对故障的心态已彻底改变。
上周,我们的一个次要服务集群出现故障。监控系统在28秒内检测到异常,45秒内完成流量切换,同时通知了值班工程师。整个过程中,零用户受到影响,零客服电话打入,零工程师需要半夜起床处理。
修复服务根本原因的工作,被安排在第二天上午的常规工作时间进行。
这就是韧性架构带来的真正自由——从被故障追着跑的被动反应,到主动设计能够承受失败的系统。我们不再追求完美的不败金身,而是构建能够快速恢复的有机体。
如果你也在为系统稳定性而挣扎,记住这个简单的真理:停机不是失败,无法从停机中快速恢复才是真正的失败。每一次故障都不是技术债务的利息,而是系统韧性进化的养料。
开始你的韧性之旅,可以从明天早上的站会开始,问团队一个问题:“如果我们的数据库现在崩溃,用户需要多久才能感知?系统需要多久才能自愈?”
答案可能会让你惊讶,而改变,就从这份惊讶开始。