

当一家公司的CTO在季度董事会上被问及“我们的系统到底有多健壮”时,他的回答竟是一串不确定的修饰词和精心挑选的局部指标——因为没有任何框架能让他量化那个真正重要的答案。
我们都有过这样的时刻:看着监控面板上跳动的绿色指标,却隐隐感到不安;处理完一次看似“偶然”的故障,却预感它会在某个周末卷土重来。这种不安,源于我们缺乏一个全景式的、可量化的架构健康度评估体系。
传统的评估方式存在七大盲区:过度关注资源利用率而忽视业务适配度;只测峰值性能而忽略常态韧性;评估单点能力却无视系统耦合;检查静态配置却不察动态演进能力;盯着技术指标却忘了团队认知与系统的匹配度;关注预防能力而轻视故障下的自愈;以及最危险的——用过去的成功经验线性推演未来的复杂挑战。
这份十维诊断清单,正是为了照亮这些盲区而生。它不仅是体检工具,更是一份架构进化的导航图。
维度一:资源效率与业务适配度
核心问题:你的资源消耗是否精确匹配业务价值流动?
评估方法:计算“业务价值密度”——即每单位核心业务交易(如一笔订单、一次视频转码)所消耗的CPU秒、内存MB和网络IO。然后对比三个数据:1)日常均值;2)促销峰值;3)行业先进实践。
常见陷阱:追求“资源利用率”这个伪指标。某电商发现其服务器CPU均值达70%,看似高效,深入分析却发现,30%的CPU周期消耗在与核心交易无关的日志处理与陈旧监控代理上。资源的高效,不等于业务的高效。
优化方向:实施基于业务语义的标签化资源调度,让每一分计算力都能追溯到一个具体的产品功能或用户场景。
维度二:安全姿态的主动性与覆盖面
核心问题:你的安全是“安检门”式的被动拦截,还是“免疫系统”式的持续监测与自适应响应?
评估方法:进行“攻击面自检”:1)绘制从外网到核心数据的所有可能路径;2)评估每条路径上的认证、授权、加密、审计是否完整;3)模拟内部权限滥用、数据泄露、服务仿冒等场景的检测与阻断能力。
一个反直觉的发现:过度严格的外部防护,可能催生更危险的内部捷径。某公司因VPN接入繁琐,导致部分团队私建未受监控的直连通道,反而成为最大漏洞。
健康信号:拥有自动化的秘密管理、服务间双向认证、基于行为的异常检测能力,并能对安全事件实现“平均检测时间(MTTD)小于5分钟”。
维度三:性能表现的可预测性与一致性
核心问题:你的系统响应时间是“玄学”还是可预测的科学?
评估方法:不看平均响应时间,而分析长尾延迟(P99, P999) 的分布与成因。在固定负载下,执行连续24小时的压力测试,观察响应时间曲线的平滑度。引入“性能衰减系数”——系统在连续运行一周后,性能与刚启动时的对比。
真正的性能健康,不是跑得快,而是跑得稳。一个关键指标是“性能方差”:在95%的置信区间内,相同请求的响应时间波动不应超过平均值的20%。
维度四:韧性系数与故障自治度
核心问题:当组件必然失效时,系统是优雅降级还是连锁崩溃?
评估方法:实施定期的“混沌工程”实验,记录并评估:1)故障检测时间;2)影响隔离范围;3)自动恢复或降级成功率;4)业务层面感知程度。计算“韧性系数” = (1 – 业务影响程度) × 故障自治恢复率。
一个颠覆性视角:有计划地引入小规模故障,是预防大规模瘫痪的最佳疫苗。Netflix的Simian Army(混沌猴子)实践表明,经常经历小震荡的系统,面对大地震时存活率显著更高。
维度五:技术债务的可见性与腐蚀速率
核心问题:你知道系统中哪些部分正在“锈蚀”,以及锈蚀的速度有多快吗?
评估方法:量化以下指标:1)无法被自动化测试覆盖的代码比例;2)依赖已停止维护或存在高危漏洞的第三方库的数量与深度;3)团队公认的“无人敢碰”的模块清单及其关联业务范围;4)修复一个典型缺陷所需的平均时间与三年前的对比。
技术债务的可怕,不在于存量,而在于不可见的增量速率。建立一个“债务燃烧率”指标:每月偿还的债务点数 / 新产生的债务点数。比值持续小于1,是架构走向僵化的明确信号。
维度六:弹性伸缩的粒度与经济性
核心问题:你的扩容是精确制导的“外科手术”,还是成本高昂的“地毯式轰炸”?
评估方法:分析过去三次扩容/缩容事件:1)触发决策的指标是否直接关联业务价值?2)从决策到资源就位的平均时间;3)扩容后,目标服务的资源利用率是否达到预期?4)缩容的滞后性与由此产生的浪费。
弹性健康的最高境界,是预测性伸缩而非反应性伸缩。利用机器学习分析业务时序数据,在流量波峰到来前预扩容,在波谷来临前预缩容,将资源浪费降至最低。
维度七:数据生命周期的治理与效率
核心问题:从生成到销毁,你的数据每一刻都处在正确的位置、拥有恰当的形态吗?
评估方法:审计:1)在线生产数据库中,存放超过一年未被访问的“冷数据”比例;2)同一份数据在系统中不同形式的副本数量(存储、缓存、索引等);3)数据迁移或备份过程对在线业务造成的性能影响;4)数据销毁策略的完整性与执行情况。
数据架构最常见的健康陷阱是“只生不死,只热不冷”。建立数据分层策略(热、温、冷、冻),并自动化执行数据生命周期流转,能同时提升性能并降低成本。
维度八:可观测性的全景深度与关联洞察
核心问题:出现异常时,你是手握一张清晰的全身X光片,还是几块互不关联的局部皮肤照片?
评估方法:进行一次故障诊断演练,记录:1)从告警发出到定位根本原因的平均时间;2)需要联动多少个独立的监控工具或控制台;3)能否追溯一个用户请求穿越所有微服务、中间件和数据库的完整路径(Trace);4)指标(Metrics)、日志(Logs)、链路(Traces)能否基于统一的上下文进行关联查询。
可观测性的终极目标,是让系统达到“自解释”状态——任何异常行为,都能被现有的数据自动关联并指向潜在根因。
维度九:环境一致性与部署确定性
核心问题:从开发到生产,你的应用会不会像深海鱼一样,换个环境就“爆裂”而死?
评估方法:统计:1)去年因“环境差异”导致的部署失败或线上事故次数;2)重建一个生产等价环境所需的人工步骤和时间;3)开发、测试、预发、生产四个环境中,操作系统、中间件版本、依赖库的差异清单。
健康的技术底座,环境是代码的副产品,而非运维的手工艺品。基础设施即代码(IaC)和不可变基础设施是实现这一目标的核心实践。
维度十:架构演进与团队认知的同步能力
核心问题:当架构需要进化时,是团队的知识和流程在拖后腿,还是在保驾护航?
评估方法:审视:1)最近一次重大的架构演进(如单体拆微服务、数据库分片)从决策到平稳落地的时间;2)在此过程中,产研测运各团队出现的认知摩擦与协作成本;3)架构蓝图、设计决策是否以可检索、可追溯的形式沉淀下来;4)新成员能否在两周内大致理解系统核心架构与演化历史。
这是最隐性也最关键的维度。架构的终极健康状态,是它与构建、维护它的团队之间,形成一种相互滋养、协同进化的共生关系。一个简单的衡量标准:团队讨论技术方案时,是更多引用“某某当年说”,还是引用一份持续更新的架构决策记录(ADR)。
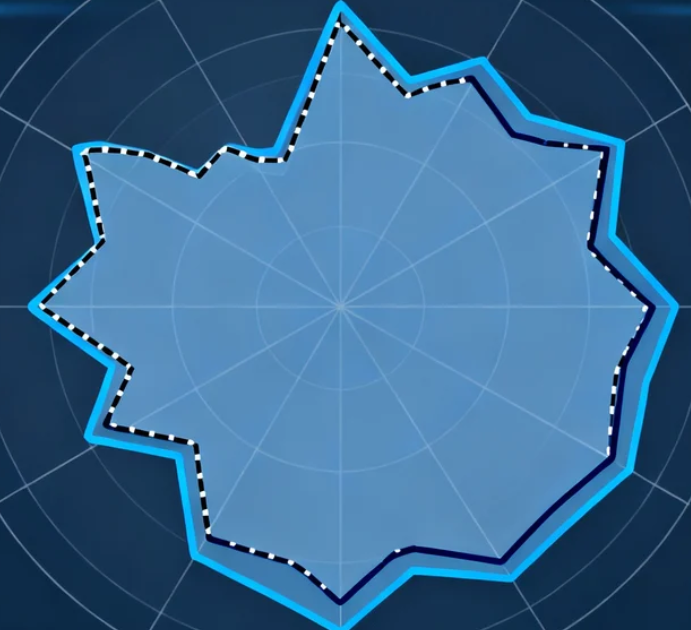
拿着这份清单,你现在可以做一件有趣的事:为你的系统在每个维度上打分(1-10分),然后连成一条线。
这条线大概率不会是一个完美的圆,而是一个凹凸不平的、有尖峰也有深谷的轮廓。这很正常,因为完美的平均是平庸的标志。真正重要的是三件事:
第一,识别出那个最短的板——它决定了你系统当下最脆弱的命门。
第二,理解深谷与尖峰背后的原因——是历史的妥协,技术的选型,还是团队的认知偏好?
第三,也是最重要的:不要试图一次性将所有的低谷填平。
技术底座的健康,是一场没有终点的马拉松,而不是一次百米冲刺。最成功的进化策略,往往是选定未来12-18个月最关键的1-2个维度,投入资源进行深度改善,同时在其他维度保持“不退化”的底线思维。
这份清单的价值,不在于提供一个完美的标准答案,而在于构建一个持续对话的框架。下个季度,当你再次被问及系统有多健壮时,你可以展示的不再是模糊的形容词,而是这条清晰、坦诚且正在向更优形态演进的轮廓线。
最好的架构,不是没有问题的架构,而是对自身健康状况了如指掌,并知道如何一步步变得更好的架构。 现在,是时候开始你的诊断了。