

一条由大模型生成的、逻辑完美的Kubernetes故障恢复指令,可能因“幻觉”包含一个早已弃用的API版本或指向一个不存在的节点——信任与灾难之间,只隔着一层未经验证的输出。
凌晨三点,你疲惫地盯着屏幕上大模型生成的故障诊断报告。报告逻辑严密,推理清晰,甚至用箭头画出了完美的故障传播路径。结论指向一个特定的微服务Pod,并给出了详细的修复命令。就在你准备复制粘贴执行的前一秒,多年运维养成的直觉让你停顿了:报告里提到的那个配置项名称,似乎和线上版本对不上。
你花五分钟手动验证,冷汗下来了——那是三个月前就已废弃的旧配置名。大模型从某个过时的技术博客中学到了它,并把它编织进了这个看似完美的“解决方案”里。
这不是科幻场景,而是正在发生的现实。当大模型开始深度介入运维的决策与操作循环,我们面临的核心挑战已不再是“AI能否理解问题”,而是 “我们能否信任AI给出的答案” 。
01 运维“幻觉”的特异性:当错误穿上逻辑的外衣
通用领域的“幻觉”可能只是提供错误的知识,但运维领域的“幻觉”直接关联着生产环境的稳定。这里需要重新定义三种专属于运维的“幻觉”类型:
实体幻觉是最危险的变种。AI可能虚构出不存在的服务器IP、已经下线的微服务、或者错误版本的API接口。更隐蔽的是配置幻觉——AI基于过时或混杂的训练数据,给出与当前生产环境不匹配的配置参数。
我曾亲见一个案例:运维工程师让AI助手处理Redis内存告警,AI给出的方案包含一行config set maxmemory 4gb命令。逻辑完美,但忽略了该集群实际使用的是Redis 6.2版本,而该参数的正确语法在6.2中已被修改。幸亏工程师多看了一眼,否则这条命令将在生产环境直接失效。
操作幻觉穿着“正确性”的伪装。AI生成的命令序列语法完全正确,逻辑自洽,却可能在错误的环境执行,或者带有预料不到的副作用。比如在数据库迁移场景中,AI建议的ALTER TABLE语句可能因遗漏某个关键条件而导致锁表时间远超预期。
因果幻觉在故障诊断中尤为常见。AI凭借模式识别能力,将表面的时间关联误判为因果联系。当多个指标同时异常时,AI可能将结果误认为原因,给出治标不治本的“解决方案”。
02 围剿战略:构建三层主动防御体系
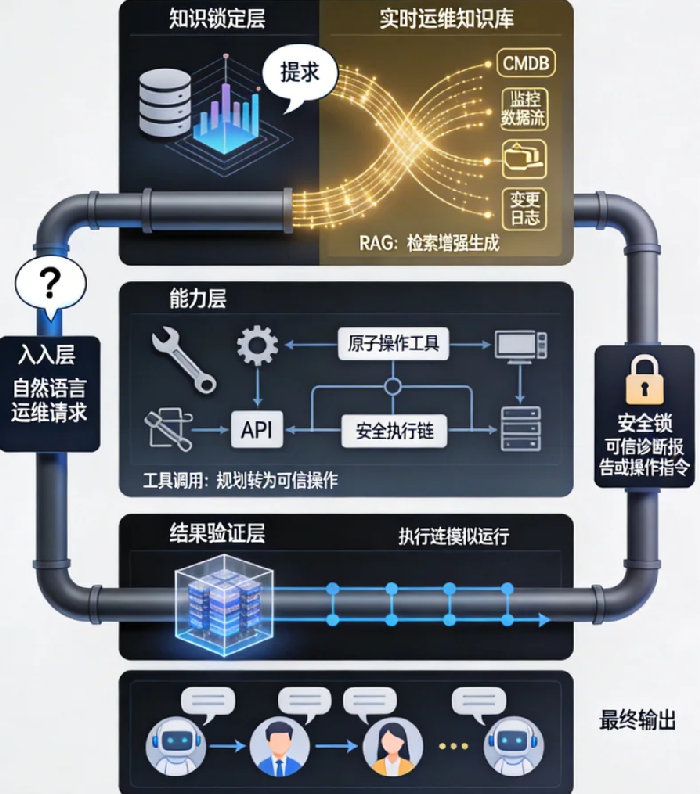
承认大模型必然存在幻觉,是设计防御体系的起点。我们需要构建的不是“防弹衣”,而是“安全操作间”——即使内部发生爆炸,也能将影响控制在有限范围内。
第一层防御:知识锚定——用你的专属数据建立真相基准
传统RAG(检索增强生成)在运维场景需要针对性强化。我们需要的不是通用知识库,而是实时更新的运维事实库,至少包含四个维度:
- 资产图谱:CMDB中的服务器、容器、网络设备及其实时关系
- 配置库:所有服务当前版本的配置文件、环境变量、启动参数
- 变更流水线:最近三个月的所有变更记录及其影响评估
- 故障模式库:历史故障的根本原因、处置过程、经验教训
这个知识库的关键特性是事实性与实时性。每次查询时,大模型必须优先从这里获取信息,并明确标注引用来源。一家中型互联网公司实施此方案后,AI生成的诊断报告中实体错误率从38% 降至7%,因为他们强制要求AI在提及任何服务器时必须附上从CMDB检索到的真实ID。
但知识锚定只能解决“知道什么是对的”,无法解决“如何做是对的”。
第二层防御:能力约束——将自由思考转化为受限执行
这是围剿战略中最精妙的一环。我们不应该让大模型直接“思考完整的运维操作”,而应该让它“思考如何组合可信的原子能力”。
具体实现是通过工具调用框架,将大模型的规划能力与经过严格测试的运维原子操作绑定。例如,我们提供这样一组工具:
query_metrics(service_name, time_range): 查询特定服务的监控指标check_service_logs(service_id, keyword, lines): 检索服务日志get_pod_status(cluster, namespace, pod_name): 获取Pod详细状态execute_safe_rollout(deployment_name, image_version): 执行安全的滚动更新
当工程师提出“检查订单服务为何响应慢”时,大模型不再生成自由文本的诊断报告,而是输出一个工具调用计划:
text
1. query_metrics("order-service", "last_1_hour") -> 分析指标异常
2. check_service_logs("order-service-*", "timeout", 100) -> 查找相关日志
3. get_pod_status("prod-cluster", "order", "*") -> 检查Pod状态
4. 综合以上信息生成诊断假设
这种模式将风险隔离在可信工具内部。即使大模型的理解有偏差,它也只能调用预设的安全操作,而无法发明危险的新命令。
第三层防御:结果验证——多重保险机制
即使经过前两层防御,我们仍需要最终的验证机制。这里有两个互补的策略:
沙盒验证针对操作类任务。对于复杂的变更方案,首先在高度仿真的沙盒环境中执行。这个沙盒不仅模拟基础设施,还模拟流量模式和数据状态。只有沙盒验证通过的方案,才能进入人工审核队列。
更创新的是多智能体辩论机制。对于复杂的诊断场景,我们同时启动多个专用智能体:
- 一个指标分析专家,专注于时序数据和异常检测
- 一个日志分析专家,擅长从海量日志中提取模式
- 一个拓扑分析专家,理解服务依赖和调用链路
- 一个经验回溯专家,从历史故障库中寻找相似模式
每个专家从自己的视角分析问题,然后通过“辩论”流程达成共识或明确分歧点。人类工程师最终查看的是这场辩论的记录,而不仅是单一结论。实验数据显示,这种多智能体辩论机制能将复杂故障的根因定位准确率提高40%,因为不同的“专家视角”能互相纠正彼此的“幻觉”盲点。
03 工程蓝图:从理论到可落地的架构
纸上谈兵终觉浅,让我们看看这个三层防御体系如何工程化实现。
数据层是整个架构的基石。需要构建统一的运维数据平台,将配置管理数据库、监控系统、日志平台、变更管理系统的数据实时同步到向量数据库中。关键技术挑战在于数据的实时性和一致性——陈旧的真相比没有真相更危险。
能力层的核心是原子工具集的设计。每个工具必须有清晰的输入输出规范、完整的错误处理逻辑和详尽的执行日志。工具集的覆盖范围需要与组织的运维成熟度相匹配,从简单的查询类工具开始,逐步扩展到变更执行类工具。
控制层是协调整个系统的“指挥中心”。它接收自然语言查询,协调RAG检索、工具调用、多智能体辩论等流程,并最终生成可信的输出。这一层需要平衡自动化程度与人工干预点——完全自动化风险太高,完全人工则失去了AI的价值。
一个可参考的开源技术栈组合是:使用LlamaIndex构建运维知识RAG,基于LangChain编排工具调用流程,利用Kubernetes临时容器创建隔离的沙盒环境。当然,核心的原子工具和业务逻辑需要根据具体环境深度定制。
04 组织与文化:比技术更难的部分
技术架构可以复制,但组织适应需要时间。构建可信AI运维管道最困难的部分往往不是技术。
技能演进是首要挑战。运维工程师需要从命令执行者转变为流程设计者与验证专家。他们不再亲自执行每一条命令,而是设计工具、定义流程、验证结果。这种转变需要系统的培训和实践机会。
流程重塑同样关键。原有的运维流程需要重新设计,以嵌入AI协作环节。变更管理、故障响应、容量规划等核心流程都需要考虑“AI作为协作者”的角色定义、职责边界和异常处理机制。
最微妙的是信任构建。团队不会一夜之间信任AI的输出。我们需要设计渐进式的信任建立机制:从只读查询开始,到建议生成,再到受监督的执行,最后才是有限度的自主操作。每个阶段都需要明确的成功指标和退出机制。
一家金融科技公司分享了他们的经验:在引入AI运维助手的第一个季度,他们要求所有AI生成的命令都必须由人类工程师手动验证执行。三个月后,他们分析发现某些类别的命令准确率已达到99.8%,于是将这些命令转为“自动执行+事后审计”模式。这种基于数据的渐进式信任建立,比任何技术方案都更有效。
回到那个凌晨三点的故障场景。如果工程师所在的组织已经建立了这样的可信AI管道,故事会有完全不同的走向:
工程师描述问题后,AI系统首先从实时知识库中检索当前服务的准确配置和拓扑信息,然后调用多个验证过的诊断工具收集数据,接着启动多智能体辩论分析根本原因,最后生成一个包含数据引用、工具调用记录和置信度评估的诊断报告。工程师审查这个透明化的过程,而不是一个黑箱结论,然后有信心地执行修复方案。
这个愿景的关键转变在于:我们不再追求“永不犯错的AI”,而是设计“容错且透明的AI协作流程”。
幻觉不会被完全消除,但可以被有效围剿。当我们停止要求大模型成为全知全能的神,而是将它视为一个需要监督和约束的强大工具时,真正的智能运维时代才刚刚开始。
最终,这场围剿战役的胜利标志,不是AI不再犯错,而是当AI犯错时,我们的系统能够安全地失败、快速地发现并优雅地恢复——这,或许才是运维智能化的最高境界。