

一份精心绘制的城市地图,在发布那一刻就已开始过时——新路开通、旧桥维修、单行道调整,而运维知识图谱面临的困境,远比这严重百倍。
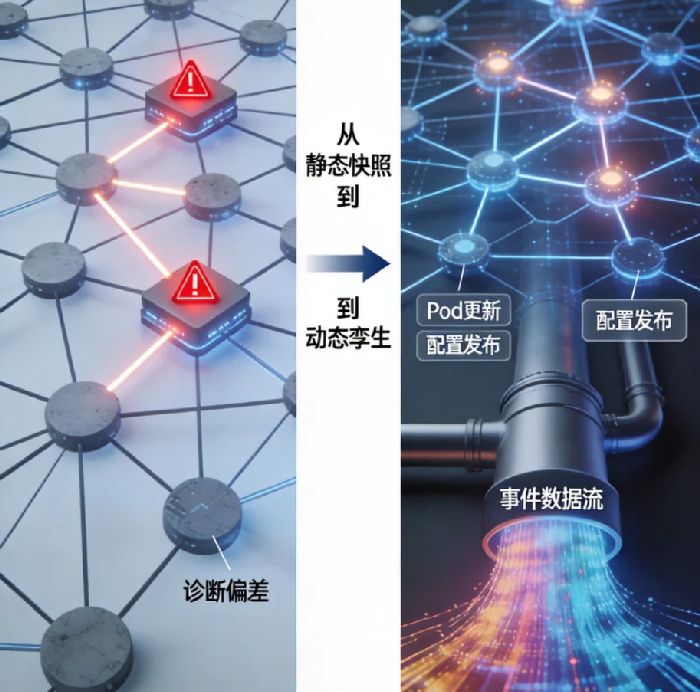
凌晨两点,一次常规的数据库索引变更后,订单服务的响应时间莫名其妙地增加了30毫秒。你的“智能诊断系统”基于一周前构建的知识图谱忙碌地分析着,它认真排查了服务链路、网络拓扑,甚至翻看了最近的错误日志,最终给出一个令人哭笑不得的结论:“怀疑是宿主机底层虚拟化性能抖动,建议重启。”
你苦笑一声,因为只有你知道,真实原因是那个新索引无意间改变了查询计划,而知识图谱里‘数据库-订单服务’的依赖权重,还停留在变更之前。
这就是我们今天要面对的核心困境:在微服务以分钟为单位滚动更新的世界里,我们却用月度甚至季度的频率来更新那张本应指导一切决策的“认知地图”。静态的知识图谱,就像用去年的人口普查数据来指挥今天的城市交通——努力的方向越正确,造成的混乱就可能越严重。
是时候为我们的运维知识图谱,装上“热加载”引擎了。
01 静默的失效:当“认知地图”落后于现实
我们得先承认一个反直觉的事实:构建知识图谱最难的部分,不是最初的绘制,而是持续的更新。据一项对50家采用知识图谱的中大型科技企业的调研,超过90%的项目在建成后的三个月内,其图谱的“事实准确性”会下降到不足70%。这意味着,每10条关系里,至少有3条已经过时或错误。
更令人不安的数据是:这些“静默失效”的关系,恰恰最容易出现在高频变更域——配置信息、服务依赖、资源映射。而当故障发生时,系统会沿着这些失效的路径进行推理,产生看似合理实则南辕北辙的诊断。
问题出在更新机制上。传统方法无非两种:定时全量重建(像每晚重新绘制整张城市地图)或人工触发更新(像市政部门接到投诉才去修改某条路的信息)。前者资源消耗巨大且总有延迟,后者则依赖人的自觉和记忆——这两者在分钟级变更的运维世界里,都显得笨拙而低效。
真正的“热加载”,要求知识图谱能像操作系统的动态链接库一样,在业务不中断、无感知的情况下,实时吸纳新知识、淘汰旧信息,并保持全局一致性。这不仅仅是“更新更快”,而是整个认知模型的演进方式发生了根本改变。
02 “热加载”引擎:分钟级更新的三块核心技术拼图
实现分钟级更新,需要一套精心设计的“事件驱动”架构。这套架构的核心,是让知识图谱从被动的“查询数据库”,转变为主动的“事件消费者”。具体来说,它由三个关键组件构成:
第一块拼图:无处不在的“变更探头”
过去,我们依赖巡检、扫描来发现变化,这就像用天文望远镜监控城市交通——周期太长,分辨率太低。现代云原生环境已经为我们埋藏了最好的“探头”:Kubernetes的控制器调和循环、服务网格的数据平面遥测、CI/CD流水线的发布事件、基础设施即代码的变更日志。
这些系统天生就在持续观察和报告状态变化。关键在于,我们需要将这些事件标准化、结构化,并注入一个统一的事件总线。例如,一次Pod的重启不再仅仅是监控系统里的一个指标点,而应该被转换为一系列事件:Pod.Terminating → PodDeleted → PodScheduled → PodRunning,每个事件都携带了完整的上下文(为什么终止、调度到哪里、新IP是什么)。
第二块拼图:智能的“图差分处理器”
接收到事件后,系统需要能理解“这对图谱意味着什么”。这需要一套“图差分算法”——它不仅能处理简单的节点属性更新(如“服务器A的IP变了”),更要能识别复杂的结构变化。
举个例子:当一次蓝绿部署完成,新版本服务B’替代了旧版本B,差分处理器需要自动完成:
- 将原有调用关系
A → B标记为“历史版本” - 建立新关系
A → B’ - 将B’的所有配置、资源关系从B继承过来
- 更新所有相关服务等级目标(SLO)的关联
这个处理器的核心是一个领域特定的规则引擎,它编码了运维领域的常识:比如“服务版本升级不会改变其功能契约”,“数据库主从切换后写入端点变化但读取端点可能不变”。没有这些规则,系统会把每次变更都视为完全独立的新实体,导致图谱迅速膨胀且失去历史连续性。
第三块拼图:分布式的“一致性协调器”
当多个变更事件几乎同时到达时(比如自动伸缩同时调整了十个服务的实例数),如何避免图谱陷入不一致状态?这需要借鉴分布式数据库的多版本并发控制思想。
每个事件都被打上逻辑时间戳,图谱为每个实体维护一个“版本链”。查询时,系统可以提供一个“一致性快照”——确保你看到的是某个逻辑时间点上完全自洽的全局状态。这种机制使得“热加载”不会因为并发更新而变得“烫手”,它保证了即使在高速变化中,图谱在任何时刻提供的信息都是内部一致的。
03 反向验证:从“记录现实”到“塑造现实”
“热加载”解决了图谱的及时性问题,但还有一个更深层的挑战:如何确保即将发生的变更,不会破坏图谱所描述的系统稳态? 这就是“反向验证”的价值——让知识图谱从被动的记录者,转变为主动的验证者。
反向验证的流程可以这样实现:
- 当一次变更(如代码部署、配置修改)被提交时,系统首先从知识图谱中提取出可能受影响的所有实体和关系子图
- 在这个“局部图谱”上模拟变更执行,评估影响链
- 调用内置的规则检查器,验证变更是否违反任何架构约束(如“单点故障”、“循环依赖”、“SLO违反”)
- 生成一份影响评估报告,标注风险等级和可能的缓解措施
一个真实的案例:某电商平台在知识图谱中编码了“核心交易链路服务不得与实验性服务有强依赖”的规则。当一名工程师试图修改一个中间件配置,无意中让交易服务依赖了一个尚不稳定的新缓存服务时,反向验证系统在合并前就发出了高级别警告,阻止了一次潜在的线上事故。
更巧妙的是,这种验证能够发现人类难以察觉的间接影响。比如,一个看似只影响前端服务的配置修改,可能因为共享了某个消息队列主题,而间接影响后端的对账服务。知识图谱的多跳查询能力,让这类“蝴蝶效应”在发生前就被暴露。
04 闭环:当知识图谱成为运维的“数字孪生”
将“热加载”与“反向验证”结合,我们得到的是一个自我修正、自我验证的活系统。它不再是我们对外部世界的静态快照,而是逐渐演变为一个与真实系统并行运行、持续同步的“数字孪生”。
这个数字孪生的价值体现在三个层面:
对工程师,它提供了一个永远最新的“系统探索界面”。你可以像使用Google地图一样,随意缩放、搜索、分析系统的任何部分,并且确信你看到的就是此刻生产环境的真实状态。
对自动化系统,它提供了可靠的决策上下文。AI运维助手在建议“重启哪个服务”时,不再依赖可能过时的配置信息;容量规划系统在预测“下个月需要多少资源”时,可以参考真实的、动态的依赖关系,而不仅仅是历史流量数据。
对组织,它沉淀了真正的架构知识。每一次变更的影响分析、每一次故障的根本原因、每一个设计决策的上下文,都被结构化的记录在图谱中,并与具体的实体关联。新成员不再是面对一堆散落的文档和模糊的口头传承,而是可以“遍历”这个活的知识库,理解系统为何是今天的样子。
05 实施的阶梯:从现在开始的渐进之路
构建这样一个动态知识图谱,不必一步到位。一个务实的实施路径可以是:
阶段一:建立核心事件管道(1-2个月)
从最关键、最稳定的数据源开始:CMDB的资产变更、Kubernetes的API服务器事件流。先构建一个最小化的图谱,只包含服务、节点、容器等核心实体及其直接依赖。这个阶段的重点是建立事件收集和处理的流水线。
阶段二:扩展领域覆盖(3-6个月)
逐步纳入更多数据源:服务网格的遥测数据、监控系统的指标维度信息、CI/CD的部署事件。同时开始编码第一批业务规则,如“关键服务必须有冗余实例”、“数据库主节点必须标记”。
阶段三:启用反向验证(6-12个月)
将知识图谱与变更管理系统集成,开始对预生产环境的变更进行影响分析。在这个阶段,重点不是阻止所有变更,而是建立信任——通过反复验证图谱预测的准确性,让团队愿意在关键决策前咨询这个“数字顾问”。
重要的是,每个阶段都要产生可衡量的价值。第一阶段可以让故障排查中的“信息收集时间”减少30%;第二阶段可以将架构审查中发现依赖问题的比例提高一倍;第三阶段则可以直接防止可能造成严重影响的错误变更。
想象这样一个清晨:你喝着咖啡,浏览着昨晚系统的所有变更报告。知识图谱没有显示任何红色警报,但有一个温和的提示:“支付服务在凌晨3点的版本更新后,其数据库查询模式发生了统计上显著的变化,虽然当前性能仍在SLO内,但建议关注后续趋势。”
你点开提示,看到一个清晰的视图:左侧是变更详情,中间是知识图谱中支付服务及其依赖的当前状态,右侧是基于历史数据对类似变更影响的预测分析。所有信息都是最新的,所有链接都是可探索的。
这不是未来的幻想,而是“热加载”知识图谱带来的现实。它意味着我们终于可以停止追逐一个永远在变化的目标,而是开始与变化本身共舞。
当你的知识图谱能够以分钟级的速度更新自己,并通过反向验证阻止破坏性变更时,你拥有的不再是一张昂贵的地图,而是一个活生生的、会呼吸的、与你的基础设施共同成长的组织记忆。
那个凌晨两点的误诊将不再发生,因为诊断系统看到的,永远是你系统此刻最真实的模样。而这,或许是智能化运维道路上,我们所能构建的最坚实的一块基石。