

一个完美的监控仪表盘,背后是三个已经静默失效的数据采集Agent——我们最信赖的“眼睛”,在最需要它们的时候,选择了集体失明。
凌晨三点,你被一阵急促的电话铃声惊醒。业务部门投诉核心交易链路出现大面积失败,而你面前的监控大屏却一片祥和——所有曲线平稳,指标绿色,宛如数字世界的伊甸园。你本能地刷新页面、检查网络、重启监控服务,但绿意依旧。直到半小时后,你偶然登录到其中一台服务器手动检查,才发现那个负责采集业务指标的Agent,已经在三天前因为一个内存泄漏悄悄停止了心跳。
此刻,一个令人毛骨悚然的现实摆在面前:我们花费数百万构建的可观测性体系,其最脆弱的环节恰恰是它自身的数据源头。当采集数据的“感官”本身失去知觉时,整个系统就进入了“睁眼瞎”的错觉状态——它以为自己看得很清楚,实际上早已目盲。
今天,我们不讨论如何分析数据,而是讨论一个更根本的问题:如何确保我们用来“看”世界的工具,自身是可靠且“可被看见”的?
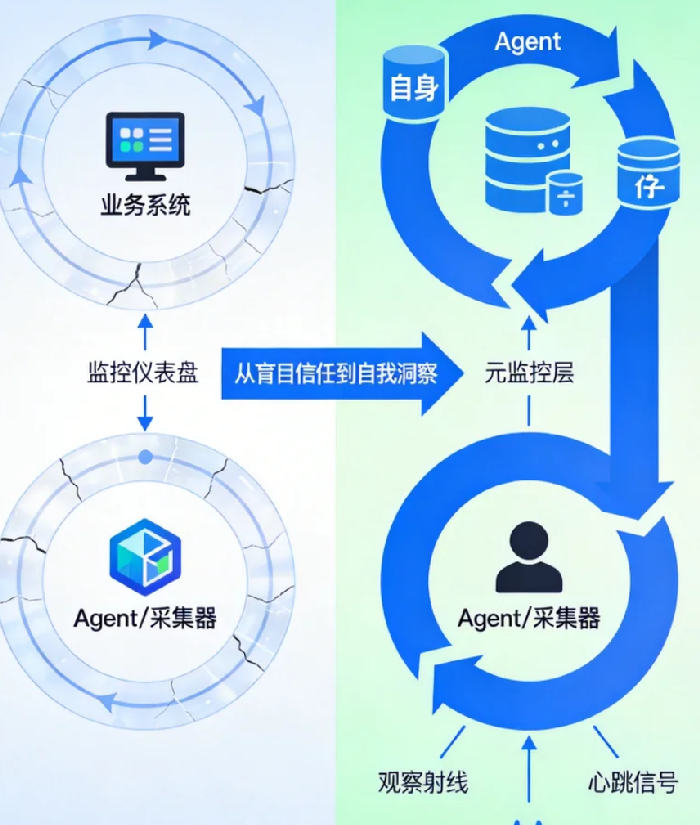
01 监控的“自指悖论”:当观察者需要被观察
在计算机科学中,有一个著名的“自指”问题:一个系统能否完全地描述或证明自身?在可观测性领域,这个问题以最务实也最危险的形式呈现:监控系统如何监控自己?
现实比理论更残酷。根据对中型互联网公司(500-1000台服务器规模)的调研,超过35%的“误报”或“漏报”事件,其根本原因可以追溯到数据采集层的问题。这包括但不限于:
- Agent因OOM(内存溢出)静默崩溃
- 采集频率被错误配置为极低值
- 网络策略变更阻断了数据上报
- 磁盘满导致日志无法写入
- 版本升级后的兼容性问题
最讽刺的是,当这些问题发生时,传统的监控系统往往浑然不觉。你的Prometheus可以报警说“MySQL连接数超标”,但当node_exporter自己挂掉导致服务器基础指标缺失时,它却保持沉默——因为它依赖的数据源头已经消失。
这形成了一个诡异的循环:我们建立可观测性是为了发现系统的未知问题,但可观测性系统自身的问题,却成为了最大的“未知”。就像用手电筒在黑暗的森林中寻找路径,却从未检查过手电筒的电池是否充足。
02 “第一公里”的复杂性:为什么数据源头如此脆弱?
要解决这个问题,我们必须先理解为什么数据采集层如此容易出问题。这不仅仅是“软件总会出bug”那么简单,而是由几个结构性因素共同导致的。
因素一:环境的极端异构性
现代基础设施像一座生态复杂的丛林。你的Agent可能运行在:
- 物理机的Systemd服务中
- Kubernetes的Pod里(可能是DaemonSet或Sidecar)
- 虚拟机内的老旧Init系统下
- 边缘设备的定制化Linux发行版上
- 甚至混合云中不同厂商的裸金属服务器
每种环境都有自己的资源约束、安全策略和生命周期管理方式。一个在K8s中优雅运行的Agent,放到物理机上可能因为缺少某些依赖库而频繁崩溃。这种环境的多样性,使得统一的健康监控变得异常困难。
因素二:资源的无情竞争
数据采集Agent往往是系统中的“二等公民”。当CPU、内存、IO资源紧张时,业务应用拥有优先权,监控Agent则被无情地限制。更糟糕的是,Agent们经常陷入自我竞争的困境:一个日志采集Agent疯狂写盘,可能导致监控Agent无法读取系统指标;一个链路追踪Agent的高频采样,可能挤占业务应用正常的网络带宽。
因素三:网络的拓扑盲区
数据采集的路径充满了单点故障。考虑这个常见场景:服务器上的Agent将数据发送到本机的日志收集器,然后由收集器批量转发到中央存储。这个链条上的任何一环中断——本地缓冲区满、收集器配置错误、网络ACL变更——都会导致数据无声地消失在“第一公里”。
一个反常规的视角是:在分布式系统中,监控数据流比业务数据流更加脆弱。业务流量有负载均衡、熔断降级、重试机制;而监控数据流往往采用“发后即忘”的UDP协议或简单的HTTP推送,丢失几个数据包被认为是“可接受的”。但当这些数据包恰好包含关键故障信号时,这种“可接受”就成了灾难的导火索。
03 元监控体系:为“眼睛”装上“镜子”
要打破这个悖论,我们需要建立一套元监控体系——一套专门用于监控“监控系统本身”的轻量级、高可靠基础设施。这不是简单的“监控监控系统”,而是一种分层的、自指的设计哲学。
第一层:Agent生命周期的“心跳监护仪”
每个数据采集Agent必须暴露一个标准化的自省端点。这不仅仅是“/health”返回200 OK那么简单,而应该包含丰富上下文:
- 采集了多少数据点?成功率如何?
- 上次成功上报是什么时间?
- 当前队列深度和内存使用情况?
- 遇到了哪些类型的错误(网络超时、解析失败、权限不足)?
更重要的是,需要一个独立于Agent本身的心跳机制。这个心跳应该极其轻量(比如一个简单的UDP包),由操作系统或容器运行时负责发送,即使Agent主进程卡死或崩溃,心跳仍能发出“求救信号”。在Kubernetes环境中,这可以通过Pod的Readiness/Liveness Probe实现,但需要更精细的检查逻辑。
第二层:数据管道的“流量监控器”
数据从采集到存储的路径必须全程可观测。这意味着:
- 在每个转发节点(如Fluentd、Logstash、OpenTelemetry Collector)设置吞吐量、延迟、错误率的监控
- 在消息队列(如Kafka)中监控消费者滞后情况
- 在存储系统(如Elasticsearch、Prometheus)中监控索引速度、磁盘使用率
关键是建立数据流的因果追踪。当一个指标在仪表盘上缺失时,你应该能像调试分布式请求一样,追踪这个数据点在哪一环节“丢失”了:是Agent没采集到?是网络中断了传输?还是存储引擎丢弃了它?
第三层:采集质量的“真实性校验”
这是元监控中最精妙的部分。我们需要定期向系统注入已知模式的测试数据,然后验证这些数据是否完整、及时地出现在监控系统中。
例如,可以部署一个“金丝雀Agent”,定期生成带有特殊标签的指标:
- “在时间T,服务器S生成了指标M,值为V”
- 然后检查在T+δ时间内,中央存储是否收到了完全一致的数据
这种方法不仅能发现数据丢失,还能检测数据篡改(如数值被错误转换)、延迟超标(δ过大)等问题。它让数据质量从“相信它应该工作”变成了“知道它确实工作”。
04 实施策略:从脆弱到韧性
构建这样的元监控体系不是一蹴而就的。一个务实的渐进式路径是:
阶段一:关键Agent的强化(1个月)
选择最关键、最脆弱的3-5个数据采集Agent(通常是业务指标和基础资源监控)。为它们实现标准化的自省端点,并部署独立的心跳监控。这个阶段的目标不是全面覆盖,而是验证模式并解决最痛的点。
阶段二:建立数据流水线的可观测性(2-3个月)
为数据流水线的每个组件添加细粒度的操作监控。重点监控队列深度、处理延迟、错误率等关键指标。建立仪表盘,可视化展示数据从源头到存储的完整流动状态。这个阶段开始形成系统的“元视野”。
阶段三:实施主动验证(3-6个月)
部署金丝雀测试系统,开始定期验证数据管道的完整性和时效性。将验证结果转化为SLA指标(如“数据完整性>99.9%”、“数据延迟<30秒”),并设置告警。这个阶段让数据质量从定性走向定量。
阶段四:闭环与自治(持续)
将元监控发现的问题反馈到自动化修复流程中。例如:
- 当检测到Agent静默失败时,自动重启或重新调度
- 当数据延迟超标时,自动调整采集频率或批量大小
- 当存储接近容量极限时,自动清理旧数据或扩容
更重要的是,建立故障演练机制。定期、有意地“破坏”部分数据采集能力(如停止某个Agent、阻断某条网络路径),验证元监控系统是否能准确检测,以及自动化修复是否能正确响应。这类似于混沌工程,但专注于可观测性基础设施本身。
05 文化的转变:从信任到验证
技术方案再完善,如果没有文化的支撑,最终还是会流于形式。元监控的深层价值在于推动团队思维模式的转变:从“相信监控系统应该工作”到“持续验证监控系统确实在工作”。
这种转变体现在几个具体实践中:
将可观测性SLA纳入产品承诺
就像业务应用有可用性SLA(如99.95%)一样,关键的数据采集管道也应该有明确的SLA:“业务指标采集完整性不低于99.9%”、“日志数据从产生到可查询延迟不超过60秒”。这些SLA需要被监控、报告,并在违反时触发明确的升级流程。
建立可观测性系统的“健康度”评分卡
为整个可观测性栈建立一个综合健康度评分,基于:
- 数据采集覆盖率(有多少服务器/服务被有效监控)
- 数据时效性(从产生到可用的平均延迟)
- 数据完整性(丢失或损坏的数据比例)
- 系统资源效率(监控系统自身的开销)
这个评分应该每天计算、每周评审,成为运维团队的核心KPI之一。
培养“质疑监控”的习惯
在每次故障复盘会议中,增加一个固定环节:“我们依赖的监控数据在这次事件中是否可靠?”如果不可靠,根本原因是什么?是元监控缺失,还是告警阈值不合理?
当团队开始习惯性质疑自己的“眼睛”时,他们才真正开始理解可观测性的本质——它不是一套安装了就能高枕无忧的工具,而是一个需要持续照料、验证和进化的活的认知系统。
想象这样一个未来场景:当某个数据采集Agent因为内存泄漏开始失效时,你不需要等到业务故障发生后才后知后觉。在Agent心跳异常的30秒内,元监控系统已经发出告警;在数据完整性开始下降的1分钟内,备用Agent已经自动启动接管;在工程师被通知的5分钟内,一份完整的分析报告已经生成,指出是最近一次配置变更导致了资源竞争。
这时,可观测性系统不再是一个被动的“信息提供者”,而是一个主动的、有自我意识的合作伙伴。它知道自己什么时候“看”得清楚,什么时候“看”得模糊,什么时候可能“看”错了。
真正的可观测性成熟度,不在于你能收集多少数据,而在于你对自己所收集数据的可信度,有着多么清醒和量化的认知。
当我们为可观测性的“第一公里”装上了“镜子”,我们最终获得的不仅是一套更可靠的工具,更是一种深刻的工程智慧:最危险的盲点,往往不是我们看不到的东西,而是我们以为自己能看到、但实际上已经失效的“看”的能力本身。