

我们习惯了在Kubernetes里随意kill一个Pod、给网卡增加几百毫秒延迟、让磁盘IO飙到100%。这些对基础设施的“暴力测试”,到了Serverless环境全失效了——因为你根本不知道Pod跑在哪里,也碰不到那张网卡。当函数即服务的黑盒关上舱门,我们该如何验证它到底有多抗揍?
这个问题我过去三个月被问了不下二十次。
不是来自刚刚接触Lambda的新手,而是那些已经在生产环境跑了上百个函数、经历过几次“莫名其妙全链路雪崩”的老SRE。他们的困惑很一致:过去十年积累的混沌工程工具箱,到了Serverless面前,像一整套燃油时代修车工具面对一辆没有发动机的特斯拉——每个接口都对不上,每个螺丝都拧不进。
这并非偶然。Serverless架构刻意剥夺了底层控制权,这正是它存在的价值。但“你不需要管理服务器”和“你无法测试服务器不可用时的表现”是两回事。后者是混沌工程在2026年必须回答的命题。
今天我们不谈“要不要做”,只谈“怎么做”。基于对Gremlin Failure Flags、曼波混沌套件、AWS FIS等工具的拆解,我把Serverless混沌实验归纳为三种可复制的范式。它们都不需要触碰底层虚拟机或宿主机,都在函数即服务的“黑盒”表面找到了属于自己的撬点。
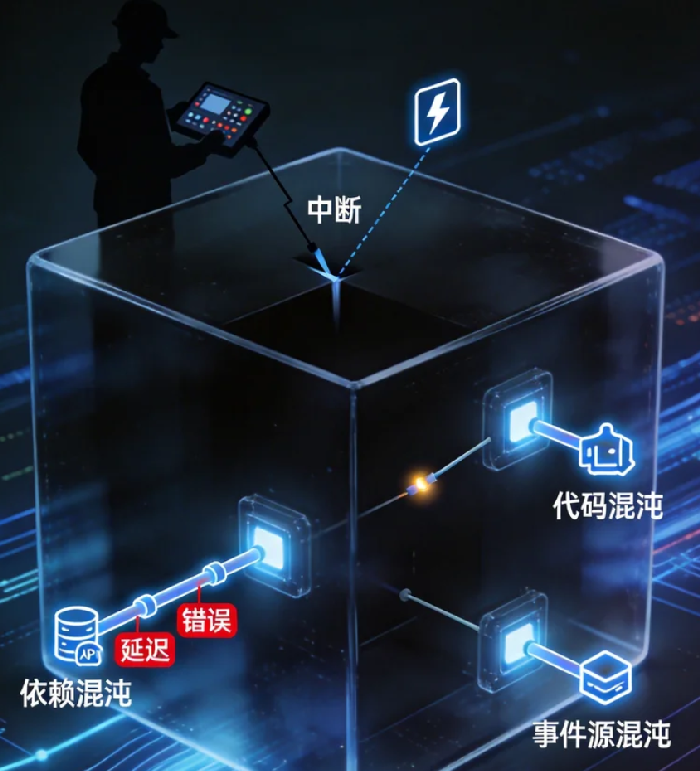
范式一:依赖混沌——把下游拖进泥潭
这是最接近传统混沌思维的一条路径,也是目前生产环境接受度最高的范式。
核心逻辑很简单:函数本身不动,让它依赖的一切出问题。
你在Lambda里调用DynamoDB,数据库响应突然慢了800毫秒;你向SQS发送消息,Broker开始随机拒绝连接;你的函数依赖第三方API,那个API在5%的请求里返回503。这就是“依赖混沌”——黑盒不动,黑盒吐出去的触手挨个被斩断。
AWS Fault Injection Simulator目前没有原生Lambda支持,但社区找到了非常优雅的替代方案。核心思路是对IAM下毒:创建一个显式Deny策略,禁止对特定下游资源的访问权限,然后在实验中动态附加给函数的执行角色。
这模拟的不是网络分区,而是权限意外吊销。在大型组织中,IAM策略错配是远比硬件故障更频繁的真实事故。
Gremlin Failure Flags走的是另一条技术路线。它在Lambda层注入SDK,通过字节码插桩或运行时拦截,在函数调用下游服务时强制插入延迟、异常或超时。这不需要修改IAM,也不需要触碰网络层,完全在应用代码边界完成。
两种方式共同的洞察是:Serverless函数与下游的每一次交互,都是一道可以被撬开的门缝。 你没有门钥匙,但可以在门缝里塞进一张写着“今天我不舒服”的纸条。
有趣的数据:某支付公司在迁移到函数计算后,通过依赖混沌实验发现,他们引用的一个第三方风控SDK在网络抖动时存在重试风暴漏洞——重试间隔过短且无退避,一次30秒的下游延迟被放大成持续3分钟的函数实例雪崩。修复后,整体SLO从99.5%提升至99.95%。
范式二:代码层面混沌——给函数装一个“微型自毁开关”
依赖混沌有盲区。如果你的故障场景是“函数自己逻辑错乱”呢?比如内存泄漏、死循环、或者随机抛出未捕获的异常?
这时候需要范式二:在函数内部植入受控的故障注入点。
曼波混沌套件(Mambo)是这一范式的国产实践代表。它完全运行在用户态,不依赖eBPF或内核模块,通过Go语言标准库的net/http、context、runtime/trace等原生接口实现故障注入。
你在HTTP handler里加三行代码:
go
if inject.Delay(r.Context(), inject.DelayConfig{
Probability: 0.05,
Min: 200 * time.Millisecond,
Max: 800 * time.Millisecond,
}) {
return // 故障已注入,正常业务逻辑被跳过
}
这行代码会随机拦截5%的请求,注入200–800毫秒的随机延迟。整个注入过程完全在当前goroutine内完成,不依赖外部Agent,也不要求特权容器。
Gremlin Failure Flags提供了类似能力,但采用声明式配置:你在控制台定义一个“向http-ingress函数注入500ms延迟”的实验,SDK在运行时检测到该Flag,自动拦截执行。
这种范式的反常规之处在于:我们把破坏性逻辑写进了生产代码本身。 这在传统运维思维里近乎禁忌——你怎么能把“制造故障”和“处理业务”混在一个代码库里?
但Serverless的部署模式恰恰让这种禁忌变得可接受。因为函数版本化成本极低,你完全可以为一个实验构建一个带故障注入桩的特殊版本,分配给1%的流量,跑完实验直接废弃。这比传统架构里在千台服务器上动态下发故障规则要安全、可控得多。
故障即代码,实验即发布——这是Serverless混沌工程独有的技术美学。
范式三:事件源混沌——在触发器的路上埋雷
Serverless函数是被动的。它们不主动工作,只对事件作出响应。HTTP请求、消息队列新条目、对象存储上传完成、定时器触发……这些都是函数的“起床铃”。
那么问题来了:如果起床铃本身坏了呢?
事件源混沌专门针对这一层。你不去动函数,也不去动下游,你污染函数被唤醒的方式。
最简单的实验:模拟API Gateway触发失败。AWS FIS可以通过修改API Gateway的路由配置,将指向Lambda的集成临时重定向到一个不存在的Mock端点,造成“后端不可达”假象。客户端看到的503错误与真实下游故障完全一致,而函数本身根本没有被执行——它甚至不知道自己被“点名”过。
更高级的玩法来自Chaos Lambda项目。这是一个纯粹Serverless的混沌引擎,本身也跑在Lambda上。你可以用它配置定时任务,随机终止指定Auto Scaling组内的EC2实例——但如果目标本身就是Lambda呢?Chaos Lambda被设计用来干扰函数依赖的底层资源,而非函数本身。它体现了事件源混沌的另一层含义:你不是函数,你是触发函数的东西,但你也可能被混沌实验波及。
这带来一个非常微妙的拓扑认知:在传统架构中,混沌实验的“靶子”是你直接管理的节点。在Serverless混沌中,靶子往往是另一个托管服务。你攻击API Gateway,它影响了Lambda;你攻击SQS的可见性超时,它让Lambda消费到重复消息。这种链式混沌是Serverless特有的复杂性红利。
三种范式的选择坐标系
你可能会问:这三条路我该走哪条?
我画了一个简单的决策树,供你在架构设计会上扔给同事:
| 维度 | 依赖混沌 | 代码混沌 | 事件源混沌 |
|---|---|---|---|
| 注入位置 | 函数调用下游 | 函数内部逻辑 | 事件触发链路 |
| 是否需要改代码 | 否(可通过SDK插桩或权限策略) | 是(需植入探针) | 否 |
| 模拟场景示例 | 数据库超时、API 503 | 内存泄漏、随机panic | API网关不可达、消息乱序 |
| 生产环境风险 | 低(可精细控制采样率) | 中(需版本隔离) | 低(可灰度发布) |
| 工具代表 | Gremlin Failure Flags, AWS FIS | 曼波Mambo, Failure Flags SDK | Chaos Lambda, API Gateway策略 |
如果你是第一次在Serverless环境引入混沌工程,我的建议是:从范式一开始,从依赖混沌入手。它最容易度量,也最容易收拢爆炸半径。范式二适合你已经建立了成熟的蓝绿部署或金丝雀发布机制,能用版本号隔离实验负载。范式三则更像一张“隐藏王牌”——当你把前三层的韧性都验证完毕,发现系统仍然在某种极端事件模式下崩溃,那很可能问题就出在事件源本身的稳定性上。
黑盒之外
Serverless混沌工程之所以让人觉得困难,是因为我们习惯了“可见即可控”的运维幻觉。我们总想看到CPU曲线、网络丢包率、磁盘IO等待时间。当我们失去了这些锚点,焦虑油然而生。
但Serverless的“黑盒”并非密不透风。它有三道缝隙——下游依赖、代码边界、事件源头——足够我们插入探针、注入扰动、观察反应。这三道缝隙对应着三种完全不同的实验范式,它们都不需要你重新获得对底层物理机的控制权,只需要你接受一个前提:
韧性不来自于对细节的全知,而来自于对未知的敬畏与充分预演。
那个困扰我三个月的问题,答案其实很简单。你不需要拆开黑盒。你只需要在黑盒表面的每个接口处,准备好你的下一场“模拟灾难”。
当你把这三类范式沉淀成组织内的实验剧本,Serverless将不再是你无法测试的“黑箱”,而是你最熟悉的“训练场”——在那里,每一次刻意的破坏,都在为下一次未知的真实故障,提前铺好红毯。
A really good blog and me back again.
Very good i like it
每日AI工具导航
wish you all the best
wish you best and best
色即是空,空即是色