

你的集群看起来“健康”——节点利用率80%,没有pending的Pod,没有报错。但你不知道的是,那80%里有一半是被“请求值”锁死的空气,而账单上的数字,正在为这些看不见的空气默默买单。
上个月和一个做FinOps的朋友喝酒,他给我看了一组数据:他们分析了100个生产集群后发现,平均每个集群有30%-40%的已分配资源从未被实际使用。这些资源被Kubernetes“预留”了,但它们只是躺在那里,像预订了座位却从未出现的客人。
更讽刺的是,这些虚占的资源往往是为了“保障SLO”——团队用double甚至triple的请求值来换取安全感。但安全感有了,账单却失控了。
传统调度器在设计时只有一个目标:把Pod放到能运行的地方。它不关心这个地方是便宜还是贵,不关心这个节点用的是Spot实例还是按需实例,更不关心你为了“安全”多预留的那2G内存正在让整个集群多租两台机器。
今天我们聊聊如何打破这种“成本失明”——让调度器不仅知道“能不能放”,更知道“划不划算”。
01 调度器的“失明症”:为什么你的集群在浪费钱却不自知
Kubernetes默认调度器的决策逻辑基于一个简单的假设:所有节点资源是同质的,所有Pod请求是真实的。但现实恰恰相反。
第一个盲点:请求值不等于使用值
这是最普遍的成本陷阱。一个典型的支付API,去年大促时峰值冲到1000m CPU,团队把request设为1000m。但今年大部分时间,它只跑150m。调度器不知道这些——它看到的是1000m的预留,于是为这个Pod保留了整个核的资源,其他Pod挤不进来,集群被迫扩容。
一个健康的Rightsizing程序通常能在稳态负载上节省15%-35%的成本。但前提是你要有勇气把请求值降到接近实际使用的水平。
第二个盲点:节点类型的价格差异
同样是2C4G的配置,AMD节点比Intel便宜20%-30%,ARM(比如AWS Graviton)能再省40%,Spot实例更是能砍掉70%-90%。但默认调度器不会主动把无状态批处理任务赶到Spot池,也不会把延迟敏感的服务留在按需节点。
第三个盲点:Bin Packing效率的隐形损耗
Kubernetes调度时倾向于分散Pod以提升可用性,这在理论上是好事。但代价是节点碎片化——一个节点剩2个核,但下一个Pod需要4核,这2个核就永远用不上了。这种碎片化的损耗,在账单上从来不会单独列出,但每月汇总时你总能感受到它的存在。
02 成本感知调度的三种策略
要让调度器变得“精打细算”,我们需要从三个层面入手。
策略一:基于真实用量的动态调权
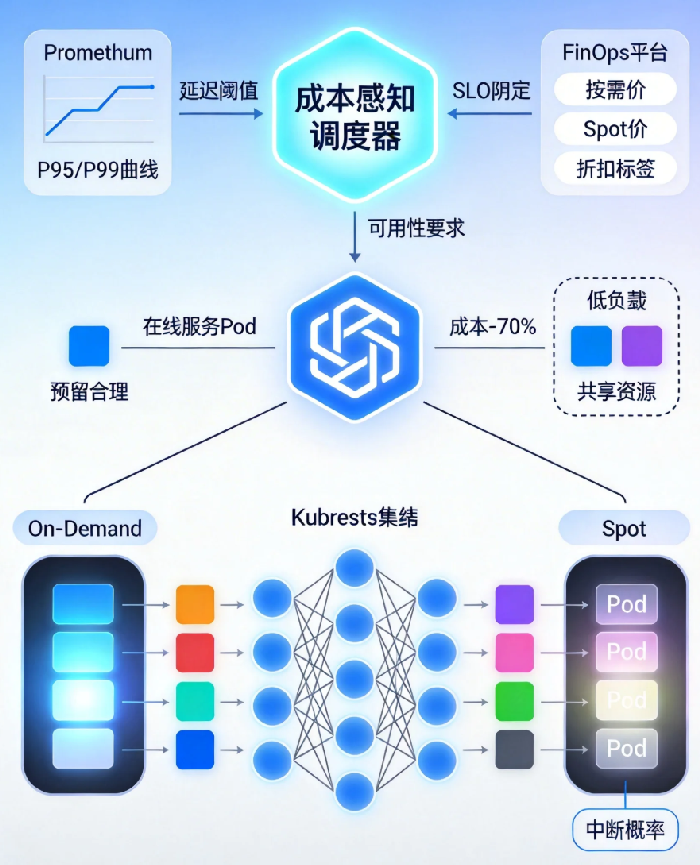
核心思想很简单:让调度器知道每个Pod的真实消耗,而不仅是它的“宣称值”。
这需要打通两条数据流:
当调度器为一个新Pod选节点时,它不再只看“剩余资源够不够”,而是算一笔账:放在A节点(按需实例)成本是X,放在B节点(Spot实例)成本是X/3,但B节点有5%的中断概率。如果这个Pod有“允许Spot”的标签,调度器会优先选择B;如果没有,则选择A但尝试Bin Packing优化。
有些团队已经开始用多维权重动态调度器,把显存连续性、NUMA亲和性、预算池余量都纳入评分体系。调度不再是一个“能或不能”的二值判断,而是一个持续优化的多目标问题。
策略二:节点池的精细化运营与混部
把集群切割成用途明确的节点池,是成本感知调度能发挥作用的前提。
典型的划分方式是:
- 在线服务池:按需实例 + 少量Spot兜底,高优先级的核心业务
- 批处理池:Spot实例为主,可以接受中断的离线任务
- 数据库池:本地SSD或高IOPS实例,固定资源
但这只是第一步。真正的进阶玩法是混部——把离线的批处理任务调度到在线服务的空闲资源上。某头部金融科技客户的实践显示,通过混部调度,GPU资源闲置率从37%降到可忽略水平,成本下降42%。
关键是调度器要能识别“空闲”的边界:当在线服务的CPU使用率低于30%时,才允许批处理任务进驻;当在线服务压力上升时,这些任务要能被优雅驱逐。
策略三:时间维度的弹性调度
成本优化的另一大杠杆是时间。大部分集群在夜里和周末利用率极低,但依然全时运行,账单照扣不误。
时间感知调度解决的就是这个问题。对于开发测试环境,可以配置定时缩容策略——晚上8点后所有非核心命名空间缩到1个副本,早上8点再恢复。对于生产环境的批处理任务,可以配置成本窗口偏好——优先在Spot实例价格最低的时间段运行。
更聪明的做法是用强化学习动态决策扩缩容:根据过去N天的负载模式,预测未来1小时的流量,决定是提前扩容保SLO,还是省点钱等到真正需要时再扩。
03 反向验证:如何在压榨成本时不压垮SLO
成本感知调度最大的风险,是省了钱但丢了SLO。缩容时切断了请求,或把延迟敏感的服务扔到了嘈杂的Spot节点上,用户的P95就会教你做人。
所以,任何成本优化动作都必须配备“反向验证”机制。
第一步:建立多维健康信号
不要只看CPU和内存。检查P95/P99延迟、错误率、队列深度——这些才是用户能感知到的SLO。缩容前,用过去14天的历史数据验证:如果当时的负载放到缩容后的资源上,延迟会超出阈值吗?
第二步:金丝雀式变更
不要一次性全量应用新的调度策略。先让5%的流量走成本感知调度器,对比这5%和另外95%的延迟和错误率。如果没问题,逐步放量。如果有问题,自动切回。
第三步:建立回滚机制
调度策略的变更要能快速回滚。这意味着调度器的决策逻辑必须是可配置的、可版本化的。有些团队已经把调度策略写成代码,存储在Git里,变更前先在测试集群模拟执行。
04 成本数据的基础设施化
最后想和你分享一个观点:成本应该成为和CPU、内存一样的一等公民指标。
我们在监控系统里会跟踪节点的CPU水位、内存水位、磁盘IO,但很少有人跟踪“成本水位”——每个命名空间花了多少钱?每个团队的成本趋势是上升还是下降?哪些服务的单位成本在恶化?
当成本数据成为基础设施的一部分时,调度器才能真正变得“精打细算”。它会知道:同一个Pod,放在A可用区因为有流量折扣,比放在B区便宜15%;它会知道:这个批处理任务如果等到凌晨2点再跑,可以用上刚释放的Spot实例,成本再降一半。
这并不遥远。KubeCost、Crane这些开源项目已经在做这件事,云厂商的FinOps工具也在快速迭代。真正的门槛不是技术,而是认知——我们是否愿意把成本当成一个值得优化的技术指标,而不是每月财务发来的账单数字。
前阵子和一个SRE聊天,他说他们团队有个不成文的规矩:每次上线前,架构师都会问一个问题——“这个设计会让单位成本变高还是变低?”
不是“能不能跑”,不是“稳不稳定”,而是“划不划算”。
我觉得这是一个很好的信号。当成本成为和稳定性同等重要的设计约束时,调度器就不再只是一个“放Pod的工具”,而是整个云原生经济的调节器。它用看不见的手,在每一次调度决策中,帮你做出那个兼顾性能与价格的最优选择。
而这,正是“成本感知调度”最终想达到的状态——让省钱变成一个自动发生的过程,而不是月末的紧急补丁。