

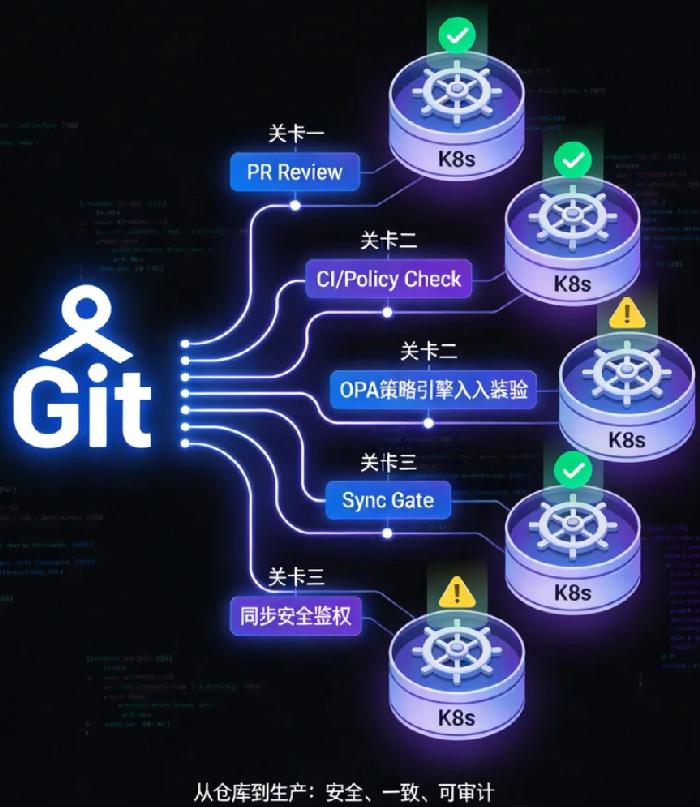
当你的集群数量超过两位数,每一次配置变更都像在雷区里跳舞——这边刚修复一个环境的镜像标签,那边的审计发现配置又漂移了;昨天还在用的部署方式,今天因为权限模型不同而失效。GitOps的承诺是“声明式交付”,但多集群的现实是“异构迷宫”。
上个月和一个管理着80个Kubernetes集群的朋友聊天,他给我看了一张截图:ArgoCD的界面里,同一个应用的配置在五个环境里呈现出五种不同的状态——不是因为故意差异化,而是因为手动修复、临时覆盖、权限错配导致的“配置熵增”。他苦笑着说:“Git说好的单一事实来源呢?现在我们有五个事实,每个都自称是真理。”
这不是个例。随着企业Kubernetes集群数量的增长,从几个到几十个甚至上百个,GitOps的简单承诺开始被现实撕开裂口:当“从仓库到生产”这条路径需要穿越环境差异、权限迷宫、同步风暴时,我们如何保证每一次交付都是安全的,每一个集群的状态都是一致的?
今天我们不谈GitOps的基础,只聊多集群环境下的进阶挑战。
01 仓库策略:当单一事实来源面临分裂
GitOps的第一原则是“Git仓库是唯一事实来源”。但在多集群环境中,这个原则马上遇到拷问:一个仓库对应所有集群,还是一个集群一个仓库,还是按某种维度拆分?
Monorepo模式把所有集群的配置放在同一个仓库里。优点是配置复用容易,全局视图清晰。缺点同样明显:当一个团队修改自己服务的配置时,可能会无意中影响其他集群;权限难以精细控制——要么所有人都能改所有集群,要么用复杂的CODEOWNERS规则,但维护成本极高。
Multi-repo模式为每个集群建一个仓库。权限隔离完美,每个集群的变更互不干扰。但代价是配置重复——同样的基础组件、同样的服务定义,需要在十几个仓库里同步修改。没有自动化的话,这就是运维噩梦。
真正的解法是一种按服务边界划分的混合模式:将共享的基础设施配置(比如监控、日志、网络策略)放在中心仓库,由平台团队统一维护;将业务应用配置按服务维度拆分成独立仓库,每个服务有自己的交付流水线。服务仓库里只包含该服务在不同环境的差异化配置,通过Kustomize或Helm引用基础配置。
这种模式既保持了单一事实来源(每个服务只有一个仓库),又隔离了变更风险(修改A服务不会影响B服务),还能通过Git子模块或OCI制品实现跨仓库的配置复用。
02 配置差异化:在标准化与灵活性之间走钢丝
即使仓库策略选对了,多集群的异构性依然会带来挑战。开发环境可能要小规模、低成本;生产环境要高可用、多副本;边缘集群可能受网络限制,无法拉取外部镜像。
GitOps工具通常依赖Kustomize或Helm来处理环境差异。但实践中,很多团队会陷入“过度参数化”的陷阱——Helm的values文件层层覆盖,最终无人能看懂最终生成的YAML是什么。
一个反常识的建议是:限制差异化手段,拥抱“配置分层”思维。
第一层是基础层:所有集群通用的配置,比如服务的基本Deployment定义、通用的ConfigMap。这一层应该尽可能少变化。
第二层是环境层:按环境(dev/staging/prod)定义的差异化,比如副本数、资源请求、镜像tag策略。这一层应该使用Kustomize的overlay或Helm的显式values文件,并且每个环境的覆盖逻辑要一目了然。
第三层是集群层:针对特定集群的特殊配置,比如某个集群需要挂载特定的存储类,或者因为底层硬件差异需要调整CPU管理策略。这一层的差异化必须被显式记录,并定期审视是否有必要继续保留。
关键是要让每一层差异都可审计、可追溯。当你在Git中看到一个变更时,应该能立刻知道它影响哪些集群、为什么需要这个差异。
03 安全同步:让最小权限原则贯穿交付链路
多集群GitOps最容易被忽视的安全风险,是同步凭证的权限过载。很多团队的做法是:在ArgoCD里配置所有集群的kubeconfig,用同一个ServiceAccount管理所有集群的部署。这意味着,一旦这个凭证泄露,攻击者可以操控所有集群。
真正的安全同步需要遵循两个原则:
原则一:每个集群独立的身份和凭证
每个目标集群应该为GitOps工具签发独立的ServiceAccount,并绑定最小必要权限。比如,只允许在特定命名空间创建Pod和Service,不允许删除Namespace。在ArgoCD中,这意味着每个集群单独配置,使用不同的credentials。
原则二:同步触发时的实时鉴权
GitOps工具在同步前应该通过Webhook或策略引擎实时验证:这个变更是否符合组织规范?是否来自批准的PR?是否有审计记录?例如,可以用Open Policy Agent(OPA)作为准入控制器,在ArgoCD向集群发送YAML前拦截检查。
更进一步,可以引入“双向认证”机制:GitOps工具必须验证集群的身份,集群也要验证GitOps工具的请求来源。在云原生环境中,这通常通过OIDC实现——GitOps工具使用JWT令牌请求集群API,集群验证令牌的签发方和受众。
04 一致性保障:当“配置漂移”成为常态
即使有严格的GitOps流程,配置漂移依然可能发生。比如:
- 有人绕过GitOps直接修改集群资源(应急恢复时手抖)
- 集群自动伸缩或自愈机制导致资源被重建,但Git中没有对应变更
- 不同集群的控制器版本差异导致行为不一致
GitOps的核心承诺是自愈——当集群状态与Git不符时,自动纠正。但在多集群环境中,这个机制需要更精细的设计。
首先,漂移检测必须覆盖所有集群。不能只依赖ArgoCD的周期性同步,而应该建立统一的监控面板,实时展示每个集群的同步状态和差异详情。当检测到漂移时,系统应自动触发告警,并记录差异内容。
其次,自动纠正需要分级策略。对于非关键资源的漂移,可以自动同步回Git状态;对于关键业务资源,可能需要人工确认后再同步,防止自动纠正导致服务中断。
最后,定期进行“GitOps混沌实验”:主动在某个测试集群中注入漂移,观察GitOps系统能否正确检测并恢复。这不仅能验证系统可靠性,也能训练团队在真实漂移发生时的响应能力。
05 可观测性:让交付过程透明可见
多集群GitOps的最后一块拼图是可观测性。你需要回答几个问题:
- 哪个集群正在同步哪个应用的哪个版本?
- 同步是否成功?如果失败,原因是什么?
- 配置变更的历史轨迹是怎样的?谁批准了这次变更?
这些问题的答案需要聚合到统一的视图。可以基于ArgoCD的API或Flux的事件系统,构建一个中央化的GitOps可观测性平台,展示:
- 全局同步状态热力图(哪些集群健康,哪些异常)
- 变更事件流(每次提交到同步的完整链路)
- 审计日志(谁、何时、改了什么、谁批准)
更进一步,可以引入SLO for GitOps:定义同步延迟SLO(比如95%的变更在5分钟内同步到所有集群)、同步成功率SLO、配置漂移率SLO。当这些指标偏离时,主动告警。
尾声:GitOps是一场交付文化的重塑
写到这里,你可能已经意识到:多集群GitOps的本质不是技术工具的堆砌,而是一场交付文化的重塑。
它强迫我们把所有配置都纳入版本控制,让每一次变更都经过评审和审计;它要求我们为每个集群建立独立的身份和权限,让最小权限原则贯彻到底;它激励我们构建统一的可观测性视图,让交付过程透明可见。
当这一切落地之后,你可能会发现:那个曾经让你头疼的80个集群,不再是80个需要分别伺候的“婴儿”,而是80个服从统一指挥的“士兵”。它们遵循同样的规范,接受同样的约束,执行同样的任务——差异不再是混乱,而是被管理的多样性。
而Git,这个诞生于Linux内核开发的古老工具,最终成为连接仓库与生产、连接开发与运维、连接规范与执行的,那条最可靠的纽带。